
本项目实现了一个基于CNN深度学习的交通标志识别系统,使用Keras构建卷积神经网络,训练准确率高达95%。系统采用Python开发,配备友好的tkinter图形界面,支持用户上传图片并自动识别交通标志类型。项目包含完整的数据预处理、模型训练、评估与部署流程,代码开源,适合深度学习与计算机视觉的学习与实践。源码与数据集均已公开,欢迎访问GitHub或Gitee获取。
项目地址:
https://github.com/dhbxs/traffic-sign-recognition
https://gitee.com/dhbxs/Traffic-sign-recognition
环境搭建
安装Anaconda
可以去官网下载Anaconda的安装包,一键安装。国内用户可能下载会很慢,建议走镜像下载站,windows用户建议默认安装就好,不要改安装路径,所有设置默认即可。
- Mac平台
https://www.anaconda.com/
清华镜像源下载 https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2020.11-MacOSX-x86%5C\_64.pkg - Windows平台
https://www.anaconda.com/
清华镜像源下载 https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2020.11-Windows-x86%5C\_64.exe - 清华镜像源汇总 https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
安装Pycharm
这里附上Pycharm官网,同Anaconda一样,默认所有设置点下一步安装即可。
https://www.jetbrains.com/zh-cn/pycharm/download/
在PyCharm中搭建深度学习环境
之前博客专门写过一期搭建深度学习环境的教程,这里不再赘述。传送门:
https://blog.dhbxs.top/archives/37561f92
创建项目
本项目托管于Github&Gitee平台,使用时可直接使用Git clone到本地运行即可。
https://github.com/dhbxs/traffic-sign-recognition
https://gitee.com/dhbxs/Traffic-sign-recognition
Clone项目
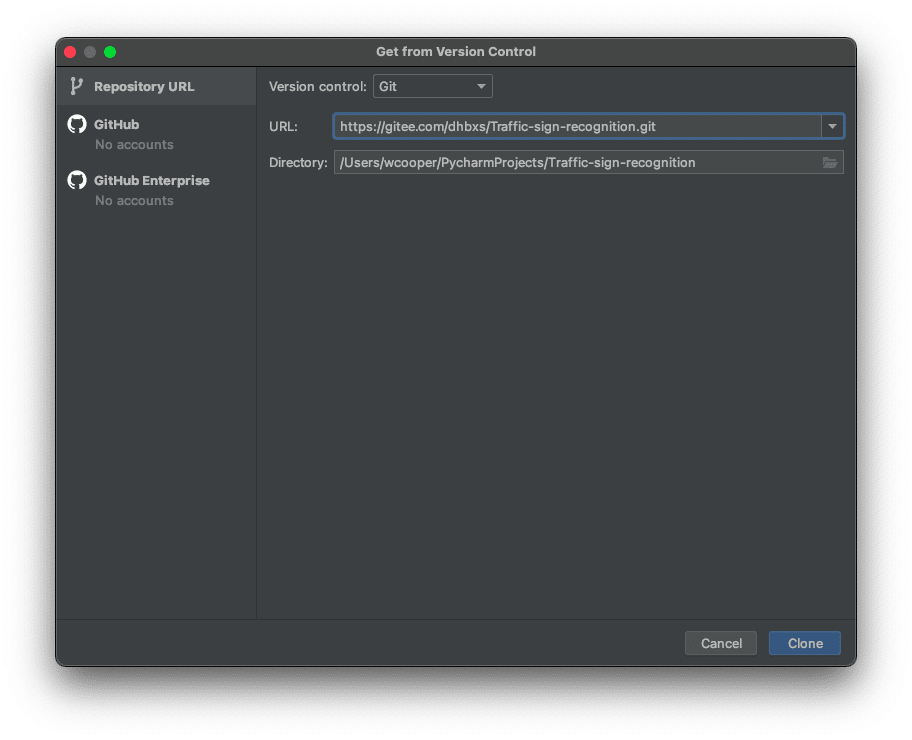
- 打开Pycharm,点击
Get from VCS按钮
- 在URL内填入
Clone地址,然后点击右下角的Clone按钮
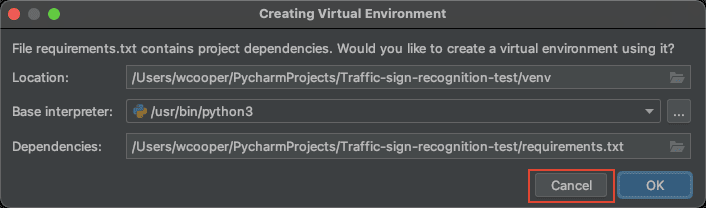
- Clone完成后,如弹出该弹窗,点击
Cancel取消创建虚拟环境,我们使用环境搭建步骤中所创建的环境:
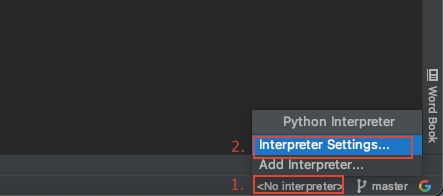
- 在右下角点击
No interpreter,然后选择Settings
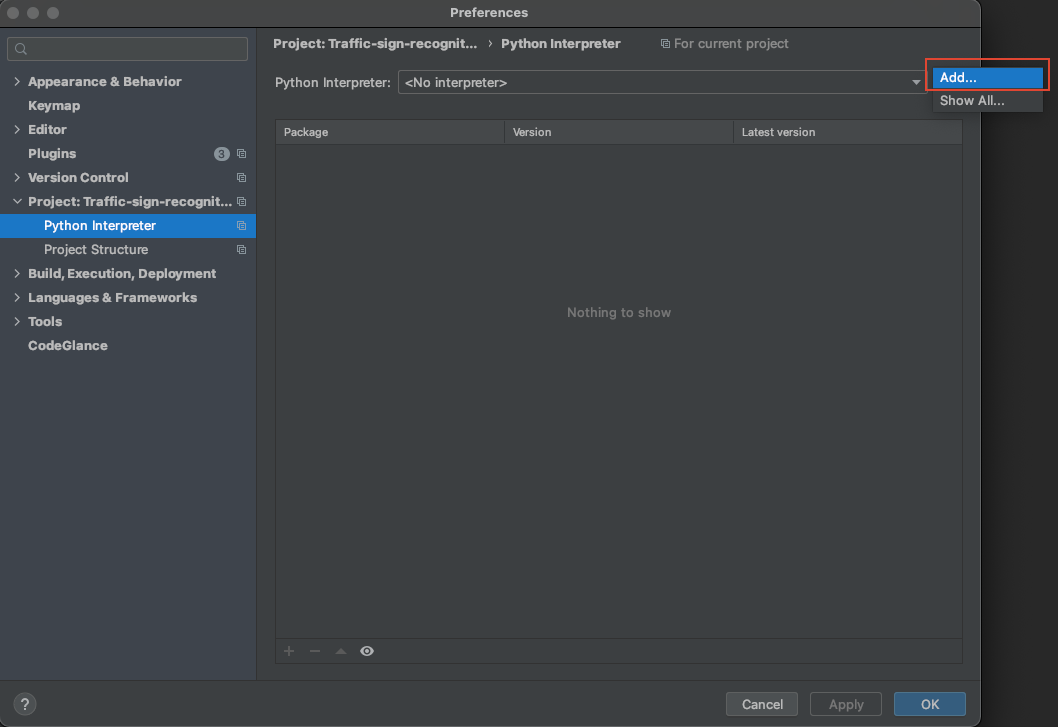
- 在弹出的页面中,选择
Add...
- 之后按如下图操作,找到环境搭建时创建的
Anaconda环境,这里为DL环境,然后选择,点击OK:
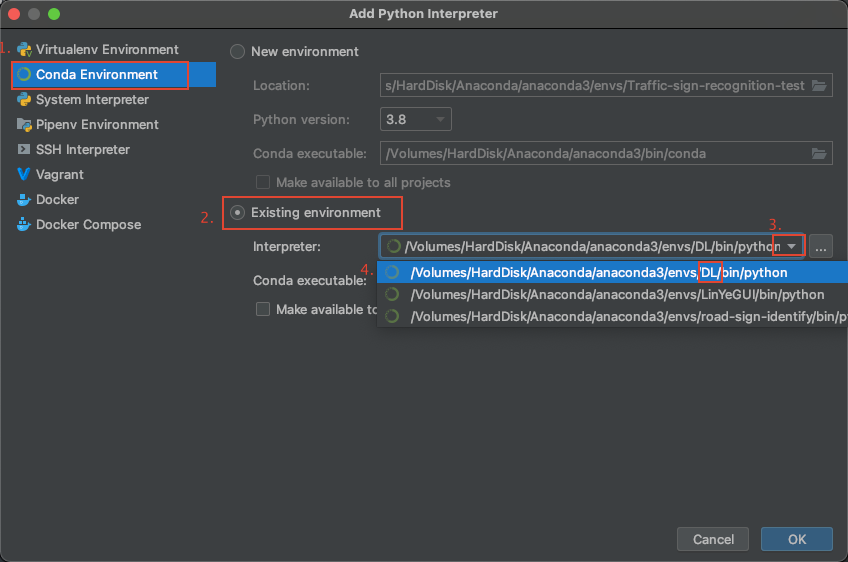
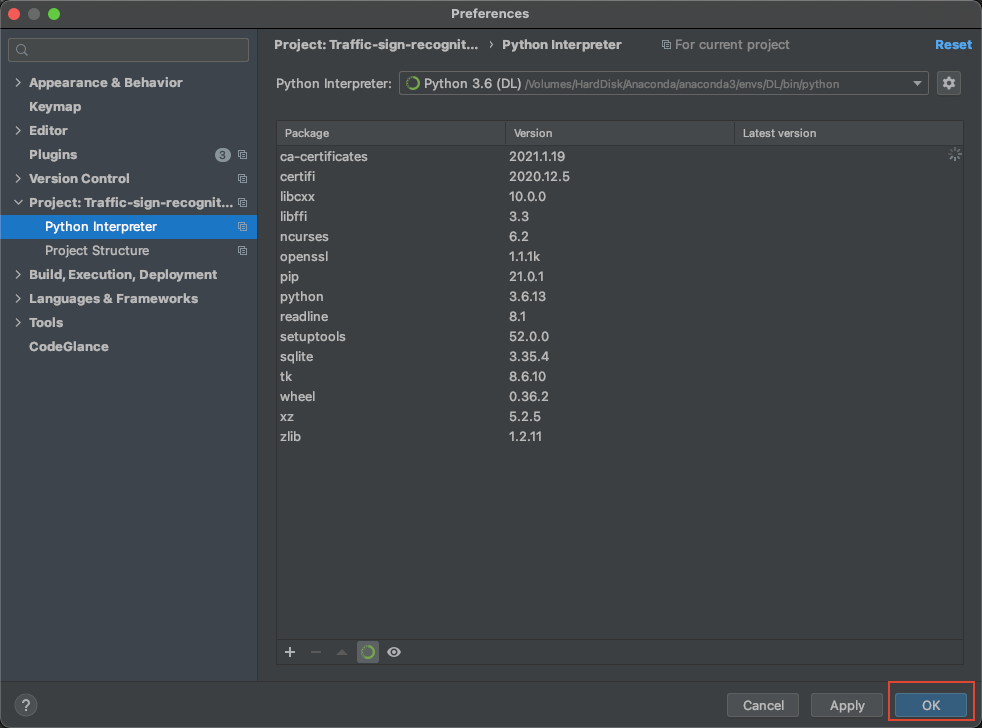
- 如图所示,点击
OK:
安装项目所需包
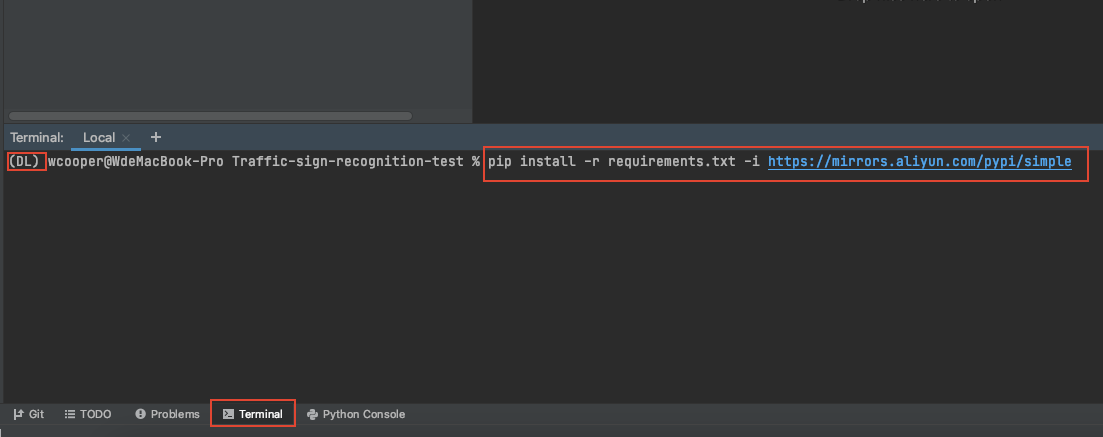
点击底部的 terminal 然后在弹出的控制台中输入以下命令,然后回车,等待安装完成:
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
下载训练数据集
- 点击以下链接,下载训练模型所需的数据集
下载地址:https://pan.baidu.com/share/init?surl=lAb9qd9jh6newMeU_HWArw&pwd=uqrg
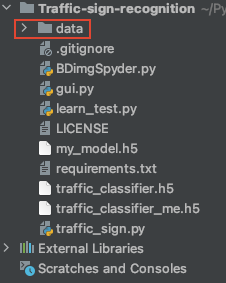
Github发布页下载地址比较快:https://github.com/dhbxs/traffic-sign-recognition/releases/download/data/data.zip - 将下载好的训练数据解压后,放到项目的根目录,如下图所示:
运行项目
用示例模型进行识别
- 双击打开gui.py文件,然后在代码空白处右击选择Run运行gui.py文件。
- 再打开的程序页面中选择上传图片
- 在上传图片对话框中选择一张交通标志图片,点击打开
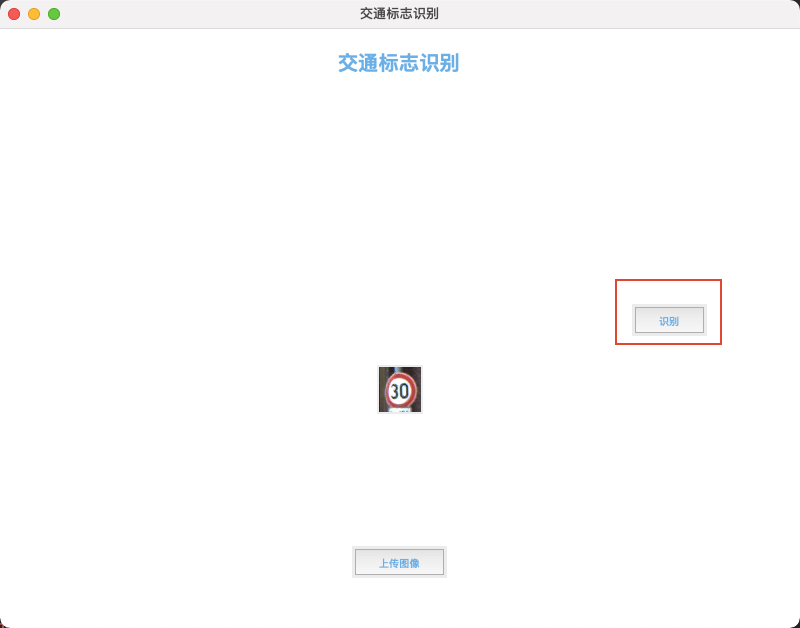
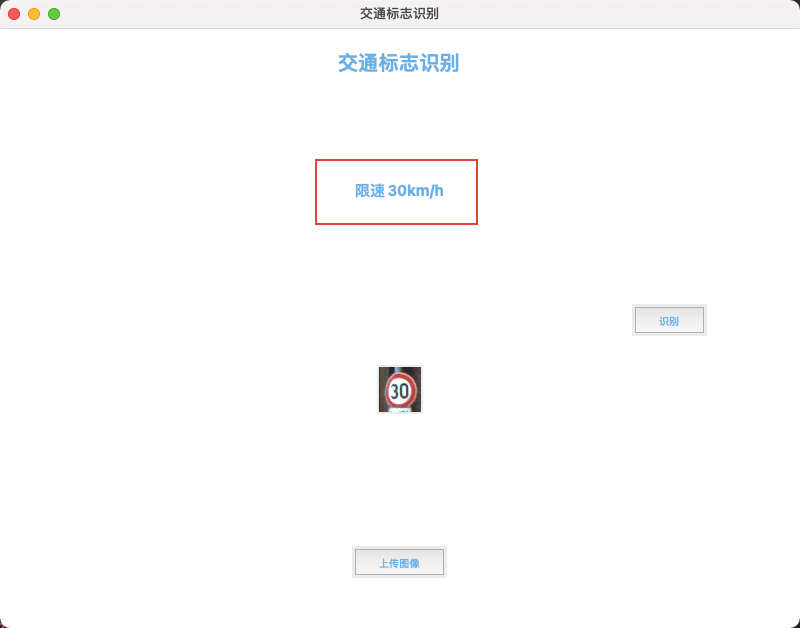
- 如片上传完成后会在页面中显示,然后点击右边的识别按钮,识别结果会显示在页面中,如下图所示
用自己训练的模型进行识别
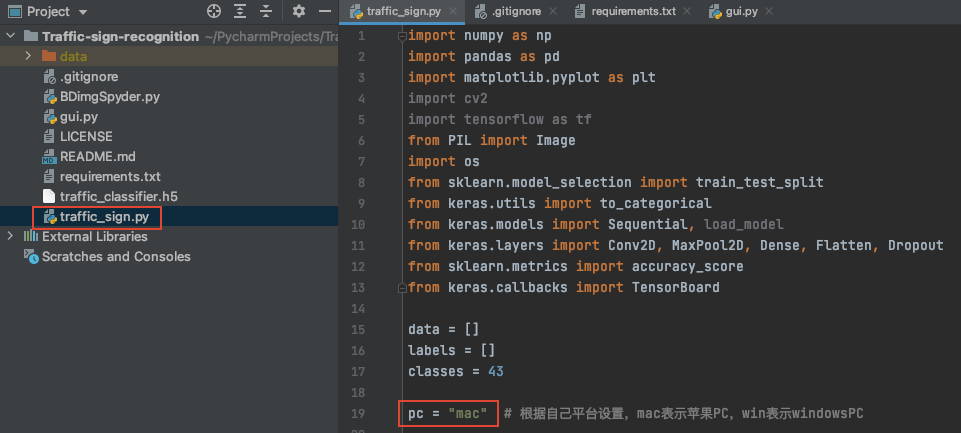
- 打开
traffic_sign.py文件 - 将如图所示代码部分修改为自己平台类型,windows平台改为win,mac平台改为mac
- 右击文件,点击
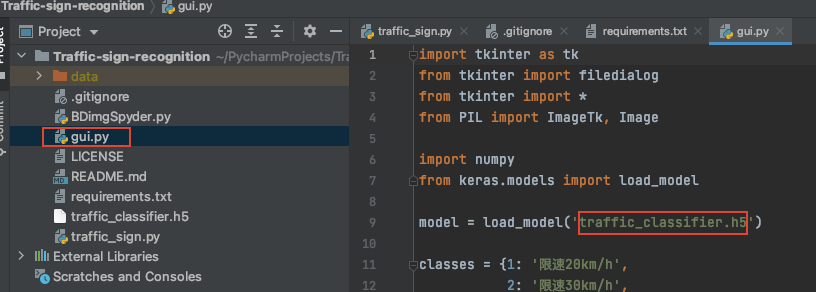
Run运行代码,运行时长与是否有独立显卡有关,耐心等待运行结束后,会生成一个名为my_traffic_classifier.h5的模型h5文件。 - 打开
gui.py文件,修改模型路径名为刚刚生成的my_traffic_classifier.h5
- 运行
gui.py文件查看效果
traffic_sign 开发文档
读取训练数据集
pc = "mac" # 根据自己平台设置,mac表示苹果PC,win表示windowsPC
不同系统有不同的路径表示方法,windows上路径都是右斜杠
\,代码中必须分开写,以提高兼容性。我目前是mac系统,在mac系统中,路径都是左斜杠/。代码中通过设置pc变量的值来区分当前运行环境。
cur_path = os.getcwd()
log_path = ""
if pc == "mac":
# 当前路径mac版
log_path = os.getcwd() + "/log"
print("当前平台" + pc)
# 检索图像及其标签
for i in range(classes):
path = os.path.join(cur_path, 'data/Train', str(i))
images = os.listdir(path)
print("正在加载第%d类训练图片" % (i + 1))
for a in images:
# mac版
try:
image = Image.open(path + '/' + a)
image = image.resize((30, 30))
image = np.array(image)
data.append(image)
labels.append(i)
except FileNotFoundError:
print("加载训练集图片出错!")
elif pc == "win":
# 当前路径设置为win版
log_path = os.getcwd() + "\\log"
print("当前平台" + pc)
# 检索图像及其标签
for i in range(classes):
path = os.path.join(cur_path, 'data/Train', str(i))
images = os.listdir(path)
print("正在加载第%d类训练图片" % (i + 1))
for a in images:
try:
image = Image.open(path + '\\' + a)
image = image.resize((30, 30))
image = np.array(image)
data.append(image)
labels.append(i)
except FileNotFoundError:
print("加载训练集图片出错!")
else:
raise Exception('print("路径设置出错!")')
通过
if判断pc变量的值,进而确定运行环境。通过for循环将data文件夹中的文件遍历后,将图片大小转换成30x30的像素大小并转换成numpy数组添加到image对象中。同时将文件所在路径保存到data列表中,以及将路径中携带的标签信息保存到labels列表中。
# 将列表转换为numpy数组
data = np.array(data)
labels = np.array(labels)
最后将
data和labels列表转换为numpy数组。
清洗数据
# 分割训练和测试数据集
# 训练集、测试集、训练标签集、测试标签集
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
# 将标签转换为一种热编码(将数据扩维)One-Hot编码
y_train = to_categorical(y_train, 43)
y_test = to_categorical(y_test, 43)
# print(y_test)
将读取到的数据按照比例,随机分割为训练集,测试集,训练标签集,测试标签集。然后采用热编码的方式,将标签集转为热编码。
建立CNN卷积神经网络模型
# 建立模型
model = Sequential()
# 添加卷积输入层 16个节点 5*5的卷积核大小
model.add(Conv2D(filters=16, kernel_size=(3, 3), activation='relu', input_shape=X_train.shape[1:]))
# 卷积层 + 最大池化层
model.add(Conv2D(filters=32, kernel_size=(3, 3), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
# 防止过拟合,网络正则化,随机消灭上一层的神经元
model.add(Dropout(rate=0.25))
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.25))
# 展平层
model.add(Flatten())
# 密集连接层
model.add(Dense(512, activation='relu'))
model.add(Dropout(rate=0.5))
# 全连接 + 输出层
model.add(Dense(43, activation='softmax'))
# 编译模型 分类交叉熵损失函数 Adam优化器 这种搭配常用在多元分类中
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
首先将模型
序列化,然后依次添加卷积输入层,卷积层,最大池化层,正则化层,卷积层,池化层,正则化层,展平层,密集连接层,正则化层,输出层。然后编译模型。
训练模型
epochs = 11
tensorboard = TensorBoard(log_dir='./log', histogram_freq=1, write_graph=True, write_images=True, update_freq="epoch")
history = model.fit(X_train, y_train, batch_size=32, epochs=epochs, validation_data=(X_test, y_test),
callbacks=[tensorboard])
model.save("my_traffic_classifier.h5")
通过
11个迭代用数据训练模型,完成后保存训练后的模型。
绘制图像
# 绘制图形以确保准确性
plt.figure(0)
# 训练集准确率
plt.plot(history.history['accuracy'], label='training accuracy')
# 测试集准确率
plt.plot(history.history['val_accuracy'], label='val accuracy')
plt.title('acc')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.legend()
plt.show()
plt.figure(1)
plt.plot(history.history['loss'], label='training loss')
plt.plot(history.history['val_loss'], label='val loss')
plt.title('Loss')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.legend()
plt.show()
用
matplotlib工具绘制准确率以及损失函数图像。
验证准确率
# 测试数据集的测试准确性
y_test = pd.read_csv('data/Test.csv')
labels = y_test["ClassId"].values
imgs = y_test["Path"].values
data = []
for img in imgs:
image = Image.open(img)
image = image.resize((30, 30))
data.append(np.array(image))
X_test = np.array(data)
pred = model.predict_classes(X_test)
# 测试数据的准确性
print(accuracy_score(labels, pred))
读取从未被神经网络学习过的新数据,以验证识别准确率。

评论区
评论加载中...