📌 耗时将近 1 天,终于搭好了 Hadoop 集群,现做教程分享出来。
本文基于 MacOS Big Sur 11.2.2 操作系统,配置 3 台 CentOS 7 虚拟机,部署 Hadoop-2.7.7所有安装文件集合下载:百度网盘 提取码:o7k4
安装 VMWare Fusion 以及 TermiusSSH 客户端
VMware Fusion: 官网 https://www.vmware.com/cn/products/fusion/fusion-evaluation.htmlTermius SSH: 官网 https://www.termius.com/mac-os
我这里是通过这 2 款工具来搭建虚拟机并支持后续操作的,也可以使用其他虚拟机软件和 SSH 客户端,我是没找到 Mac 平台上能达到像 Windows 平台的 Xshell 那样的 SSH 工具。另外 Mac 也可以不使用第三方 SSH 客户端,毕竟自带的 iterm2已经很强大了。文末有用 mac 自带的 iterm 终端 SSH 连接 Linux 主机的命令。安装以上软件没什么难度,基本下一步就好。
在虚拟机中安装 CentOS 7
- 本教程所使用的虚拟机是用这个镜像安装的
CentOS-7-x86_64-Minimal-2009.iso下载地址:http://mirrors.aliyun.com/centos/7.9.2009/isos/x86_64/然后选择和我一样的镜像版本下载下来。
之前刚一开始是用的 CentOS 8,而且是全量安装,包含各种工具包,还有 GUI 图形界面,要是同时开三台虚拟机的话,16G 内存也不够,主要是 GUI 图形化窗口消耗了大量内存资源,导致系统卡顿,所以干脆就选择最小化安装了。而且安装后也不需要卸载系统自带的 OpenJDK,关键是安装也很快。Linux 玩的就是命令,要什么图形啊,服务器不都是跑的最小内核么?
1)打开 VMware Fusion,如下图,选择新建。
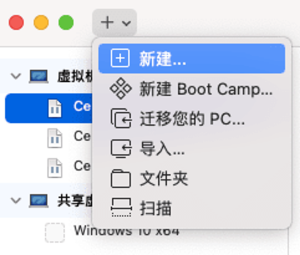
2)选择从光盘或映像中安装,然后点继续。
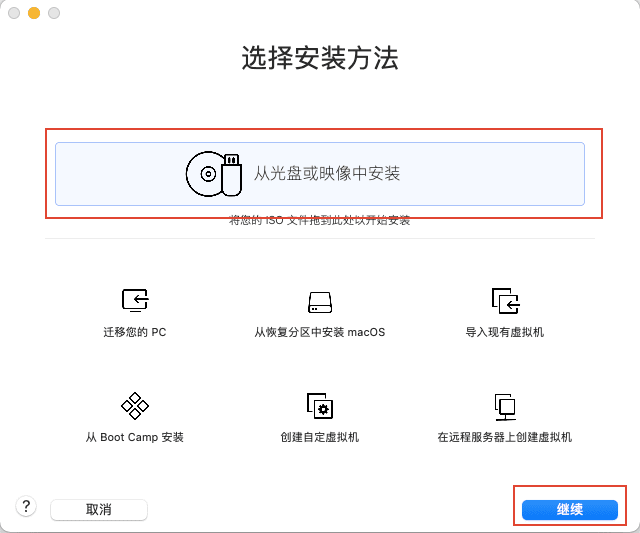
3)点击使用其他光盘或光盘映像。
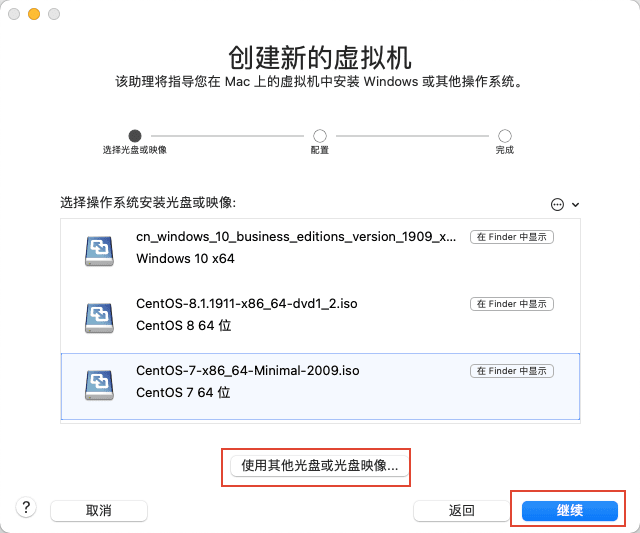
4)在弹出的对话框中,选择刚刚下载的 CentOS 7 iso 镜像文件,然后点击打开。
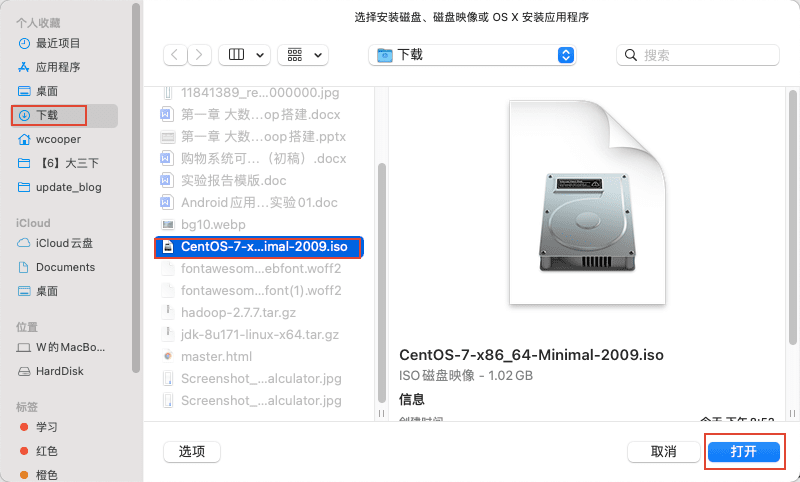
5)返回后,点击继续。
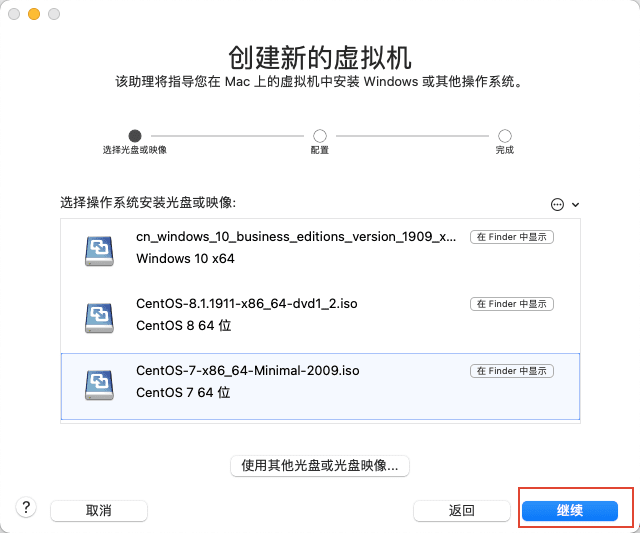
6)选择 UEFI 引导,毕竟现在的机子都是 UEFI 了,传统引导很快就会被淘汰的,不过虚拟机选啥其实无所谓,看心情喽!

7)然后点击自定设置。
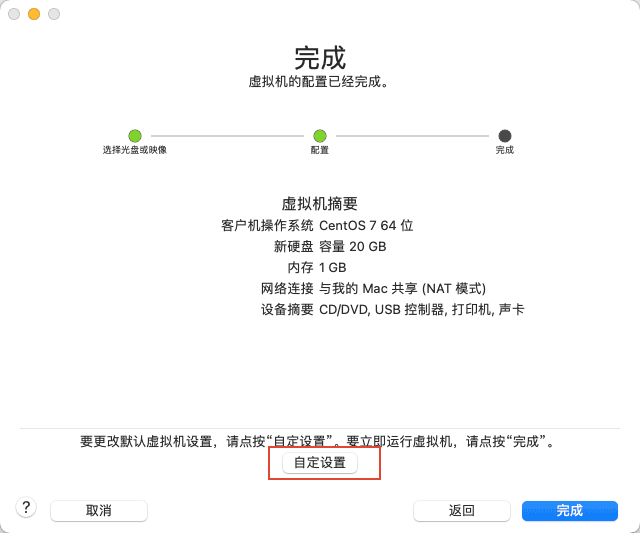
8)选择一个自己觉得合适的位置,更改个名字,将虚拟机保存,点击存储。最好放到固态硬盘中,加载速度会快些
9)在弹出的对话框中,选择处理器和内存,然后更改内存至少为 2048M 。我因为 16G 内存,所以设置了 4G,大一点系统响应速度快一些,如果电脑内存是 8G 的,那么最好设置 2048M 内存,Linux 应为没有图形化界面所以比较省内存,其实 2048M 足够了。
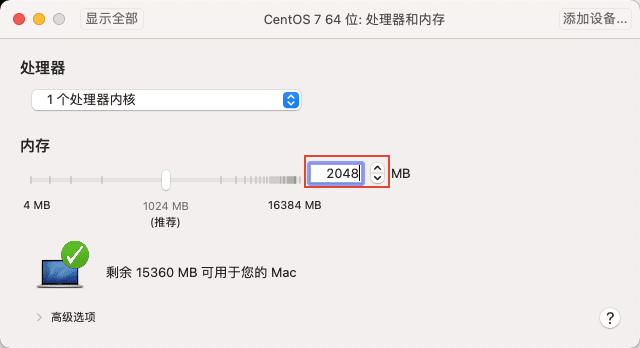
10)然后点击显示全部,返回顶层页面,点击硬盘。将硬盘大小设置为 60G , 这里视情况而定,一般至少 20G,推荐 60G,点击应用。
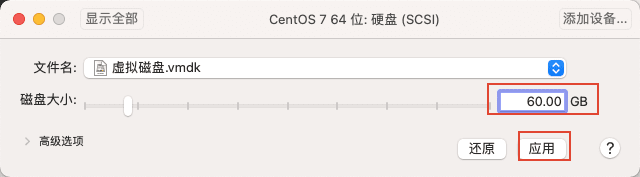
11)最后点击虚拟机的运行按钮,打开虚拟机。
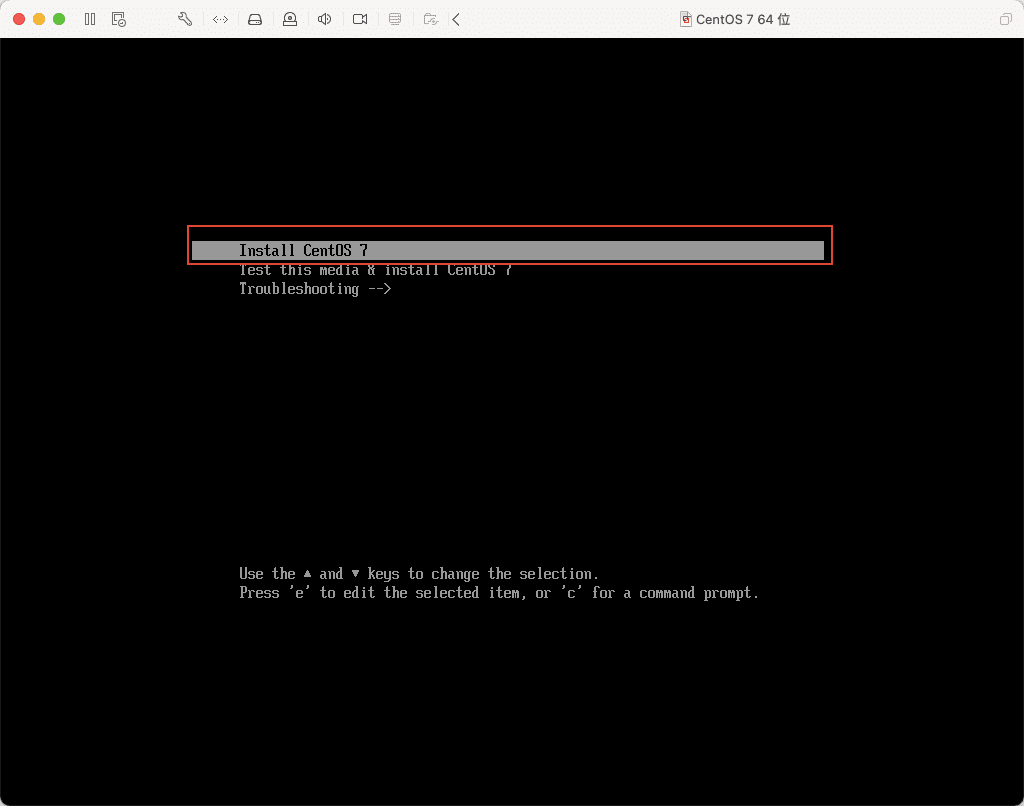
12)选择第一项,安装 CentOS 7,然后回车等待加载。
13)加载完成后,进入安装界面,语言选择中文简体,点击继续。
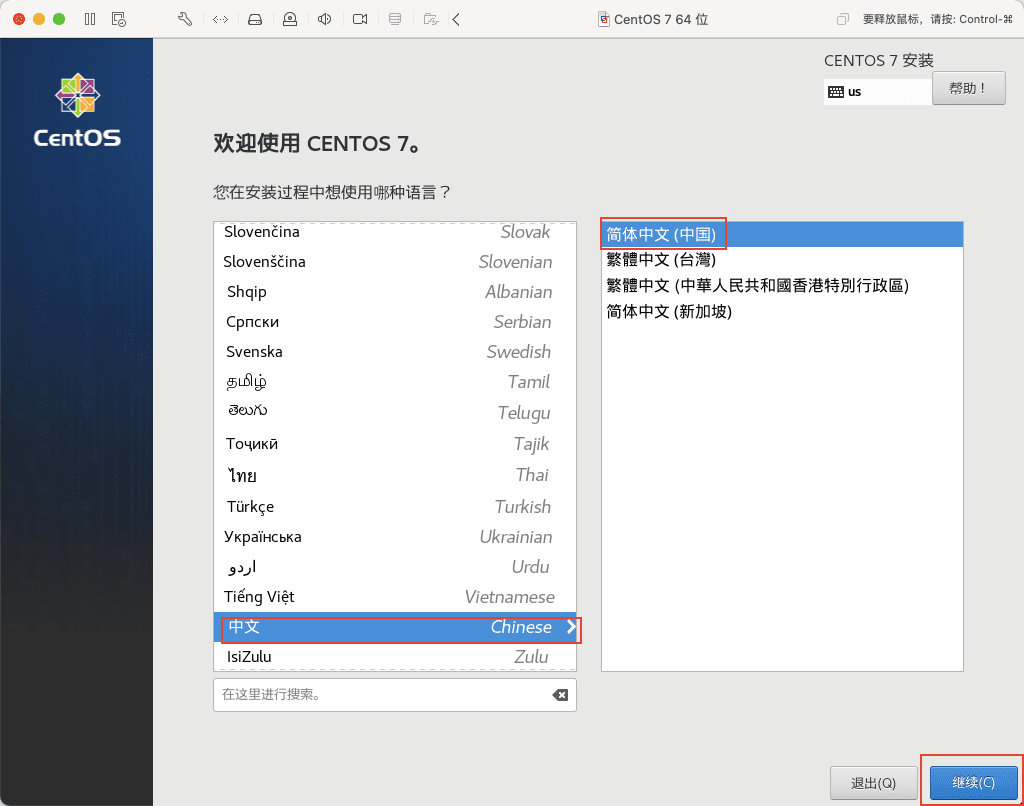
14)然后点击安装位置,以确认全盘安装。
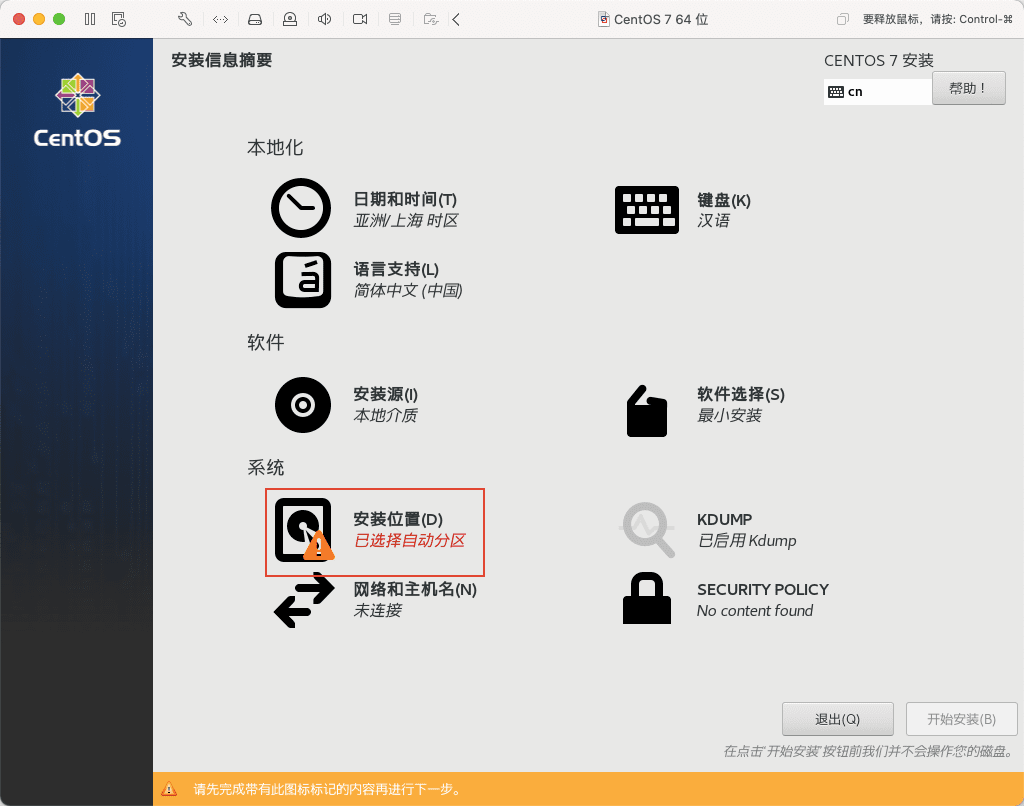
15)点击左上角的完成。
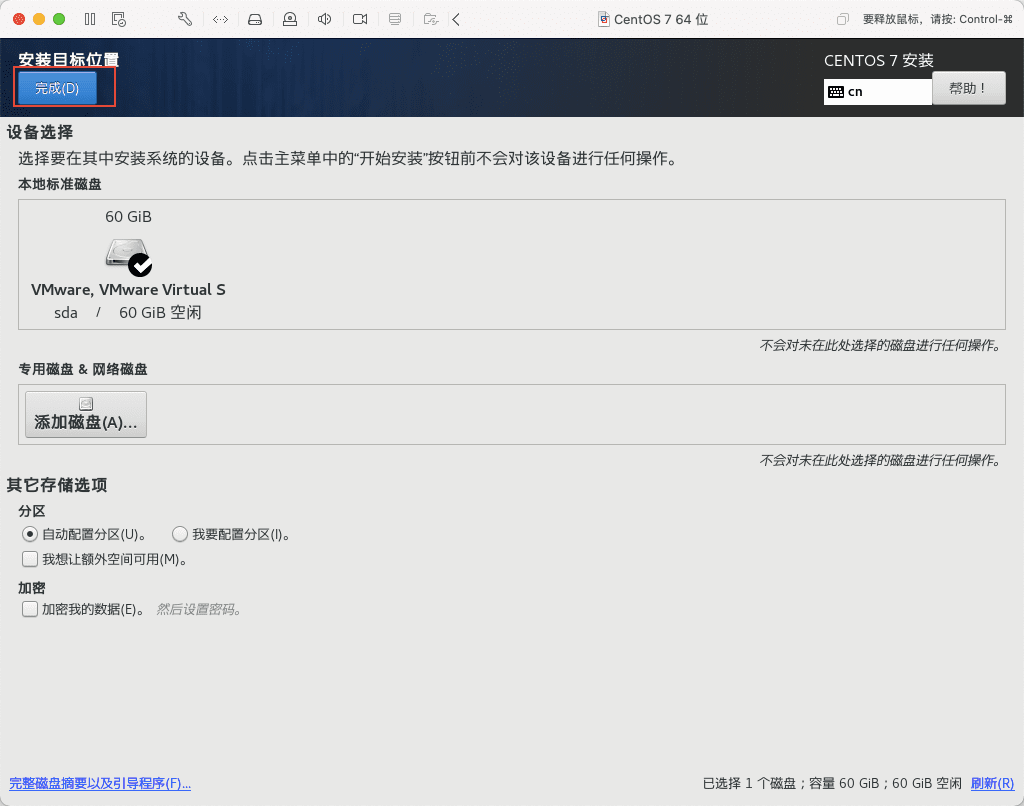
16)点击网络和主机名,配置网络和主机名。
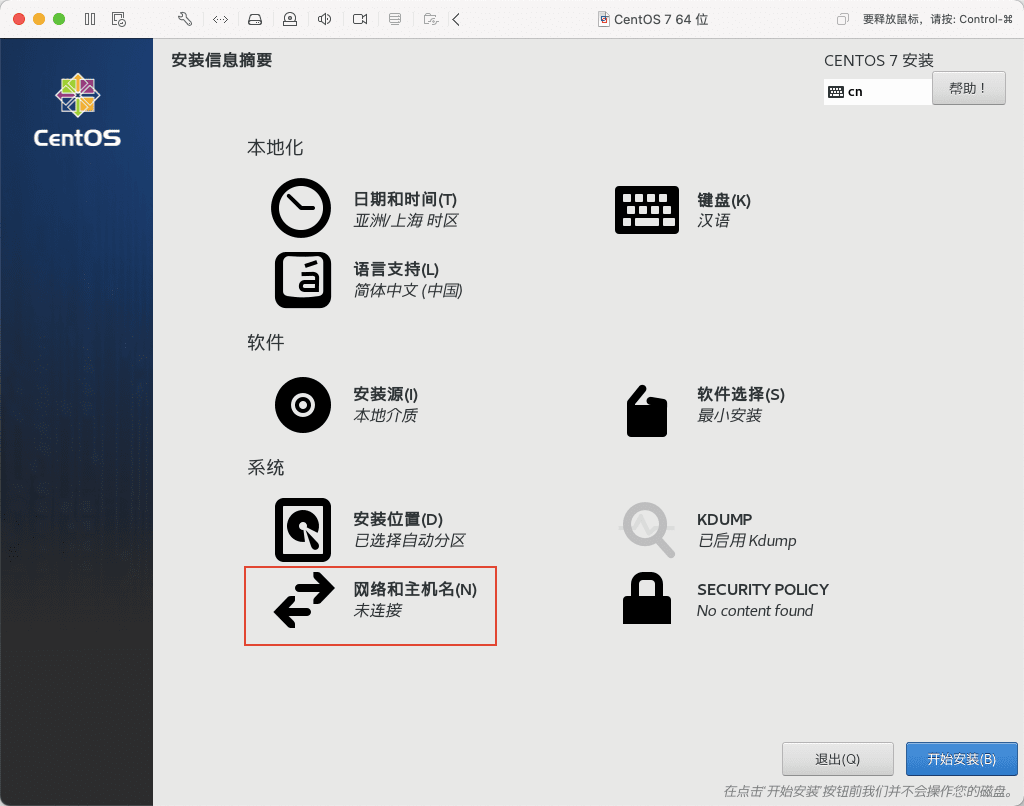
17)按下图示操作,记得拍照记录图示信息。
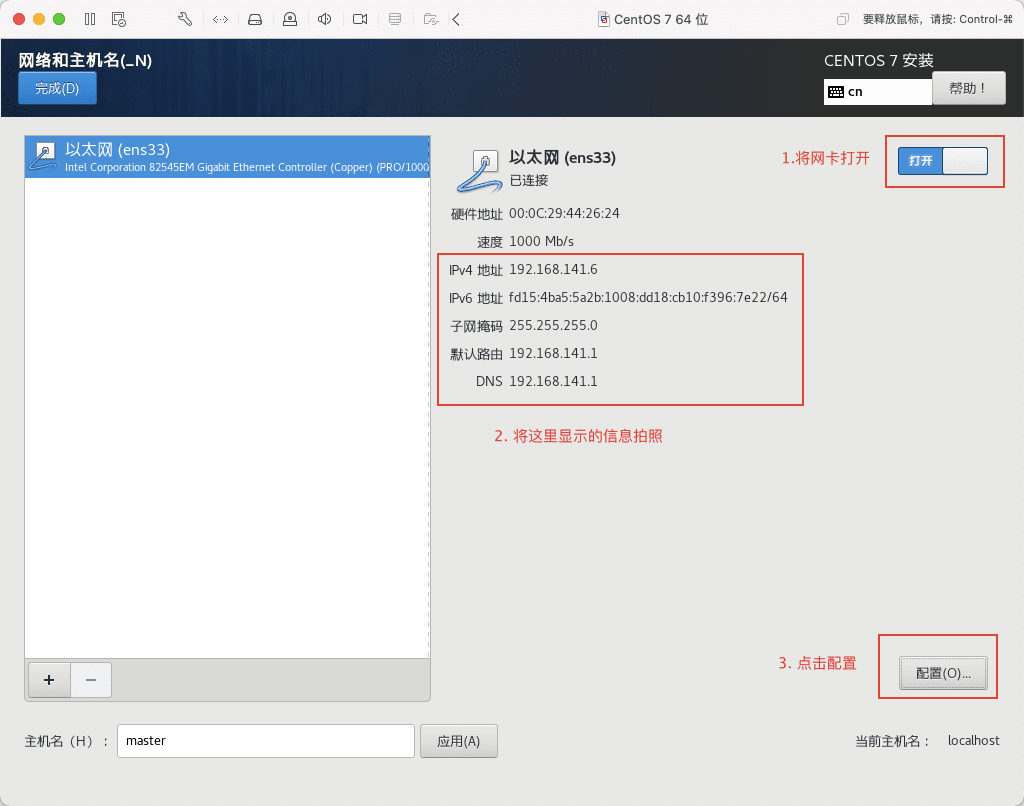
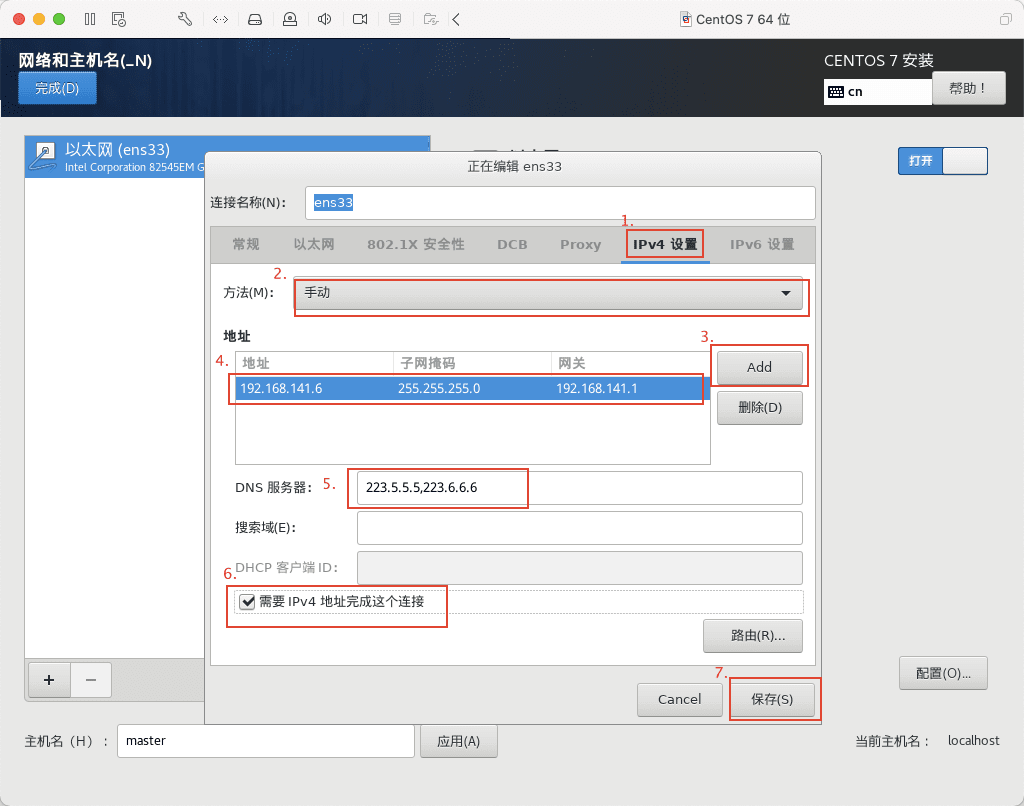
18)然后点击 IPv4 设置,将方法改为手动,目的是为了固定 IP 地址,方便以后远程连接以及 Hadoop 集群间的通信。然后点击 Add 添加地址,将地址栏填为刚刚拍照记录下来的 IPv4 地址,子网掩码同样填刚刚拍下来的子网掩码,网关其实就是路由器的 IP 了,这里填写刚刚拍下来的默认路由的 IP 地址。继续修改 DNS 服务器,我这里用阿里云的公共 DNS,将 223.5.5.5,223.6.6.6 复制粘贴到 DNS 服务器那一栏,然后勾选需要 IPv4 地址完成这个链接,最后点保存。
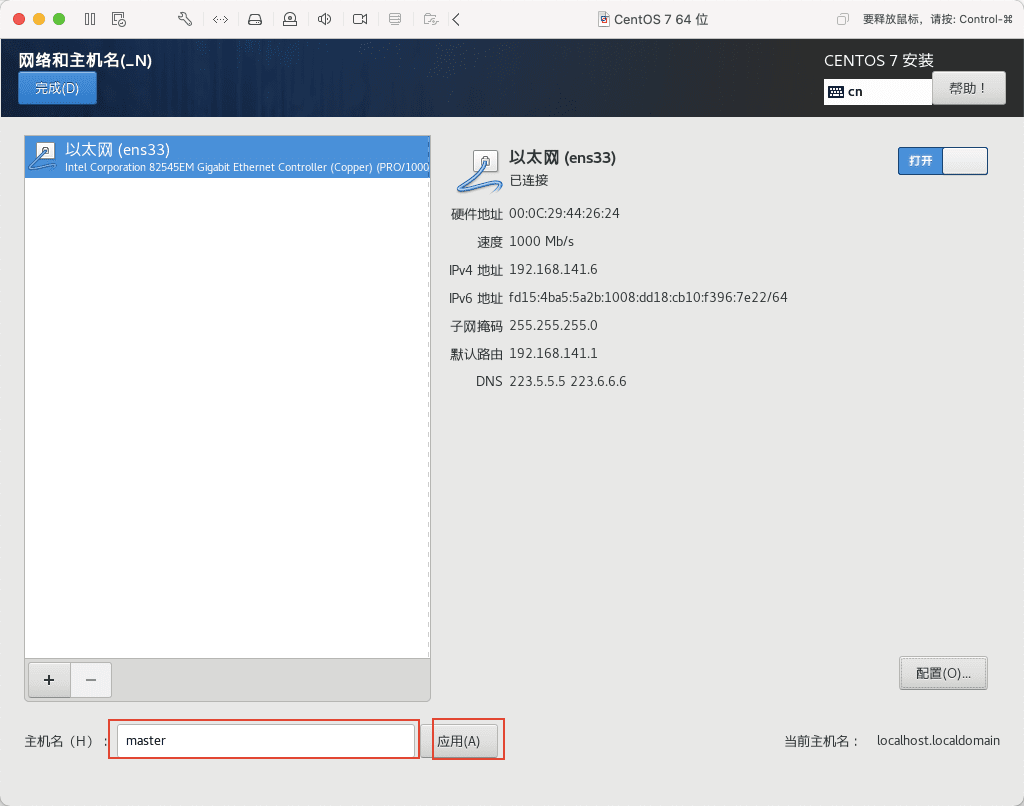
19)将主机名改为 master,我们这里现配置 master 主机,其余节点后面直接复制虚拟机即可,然后点应用。
20)按下图检查配置是否有误,无误请点击完成。
21)然后点击开始安装。
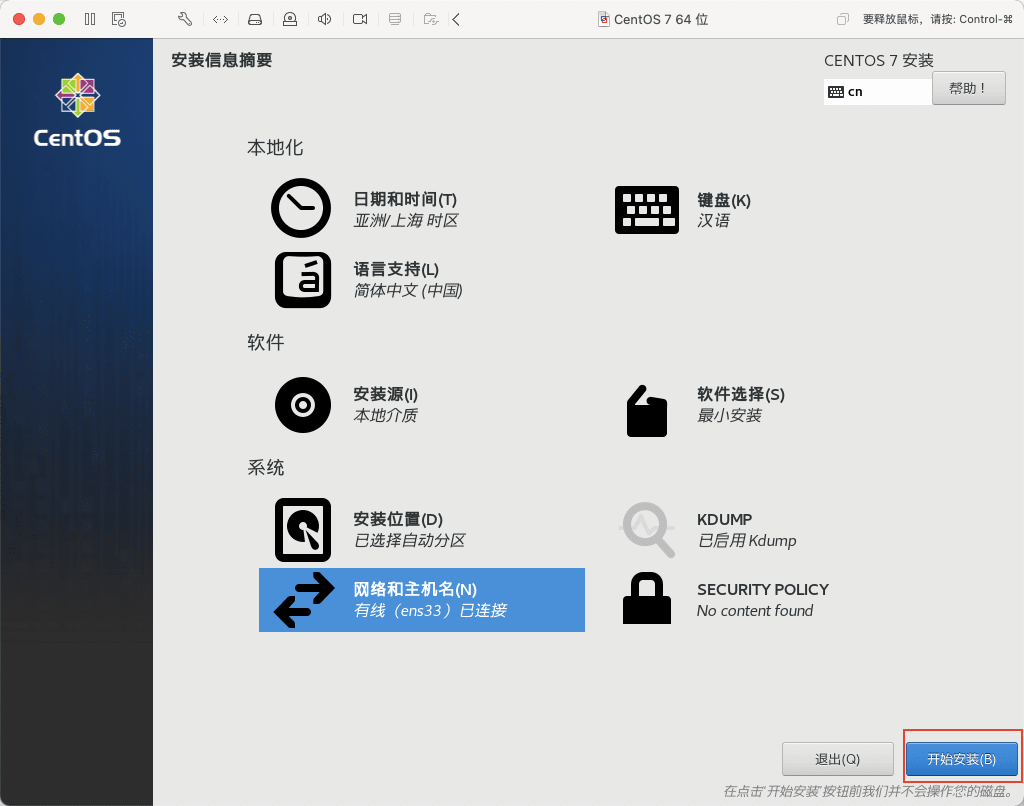
22)在安装的同时,设置 ROOT 用户和密码,点击 ROOT 密码,进入设置。
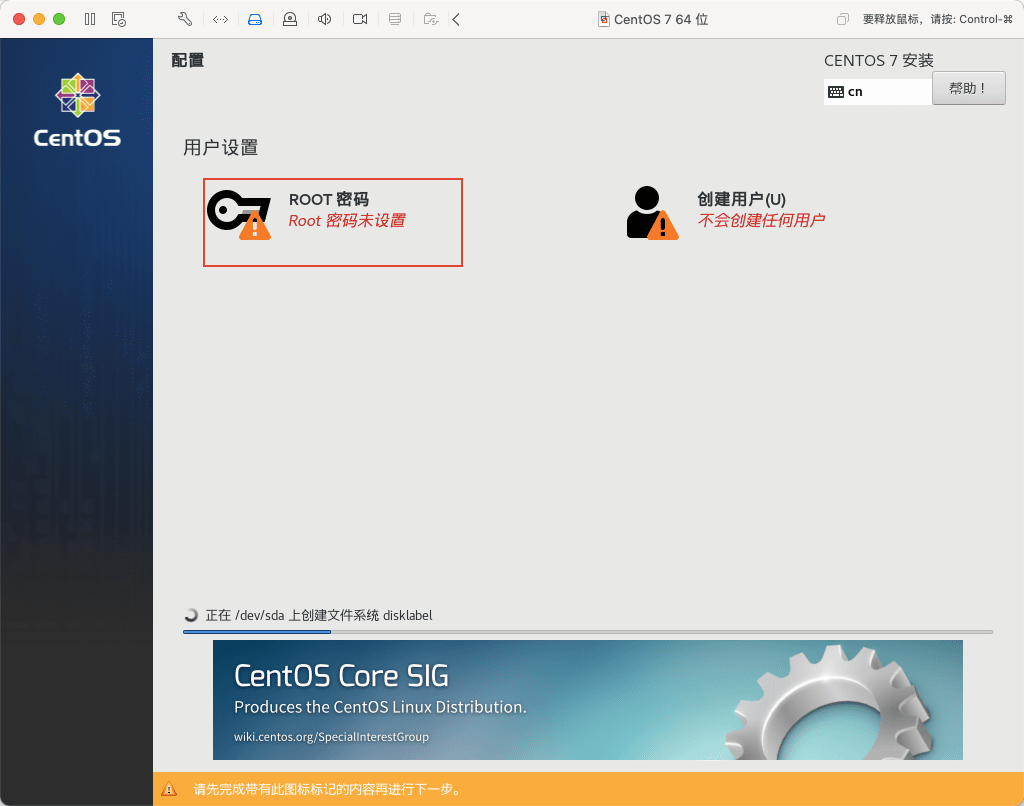
23)务必记住此密码,我这里设置为 000000 学习使用,简单点无所谓,然后点击 2 次完成,因为密码过于简单,系统会有提醒。
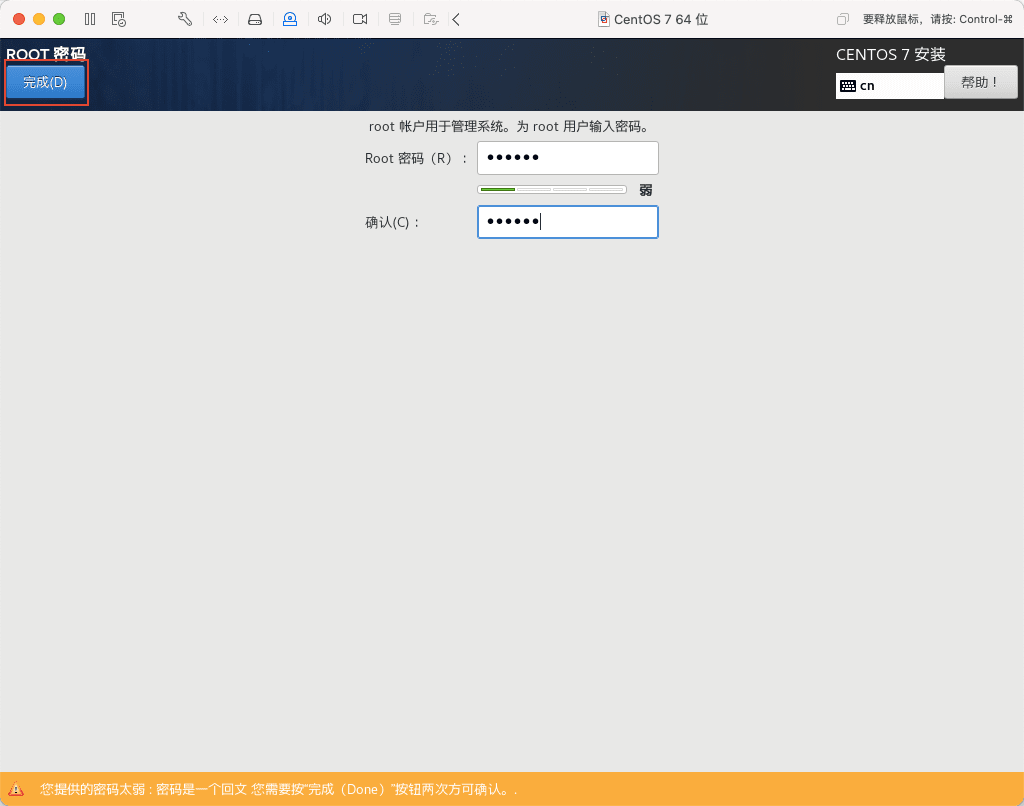
24)安装完成,点击重启,在 master login 后输入用户名 root ,然后回车,输入密码 000000。这里密码输入是不显示的,不要惊讶,以为键盘坏了!!!
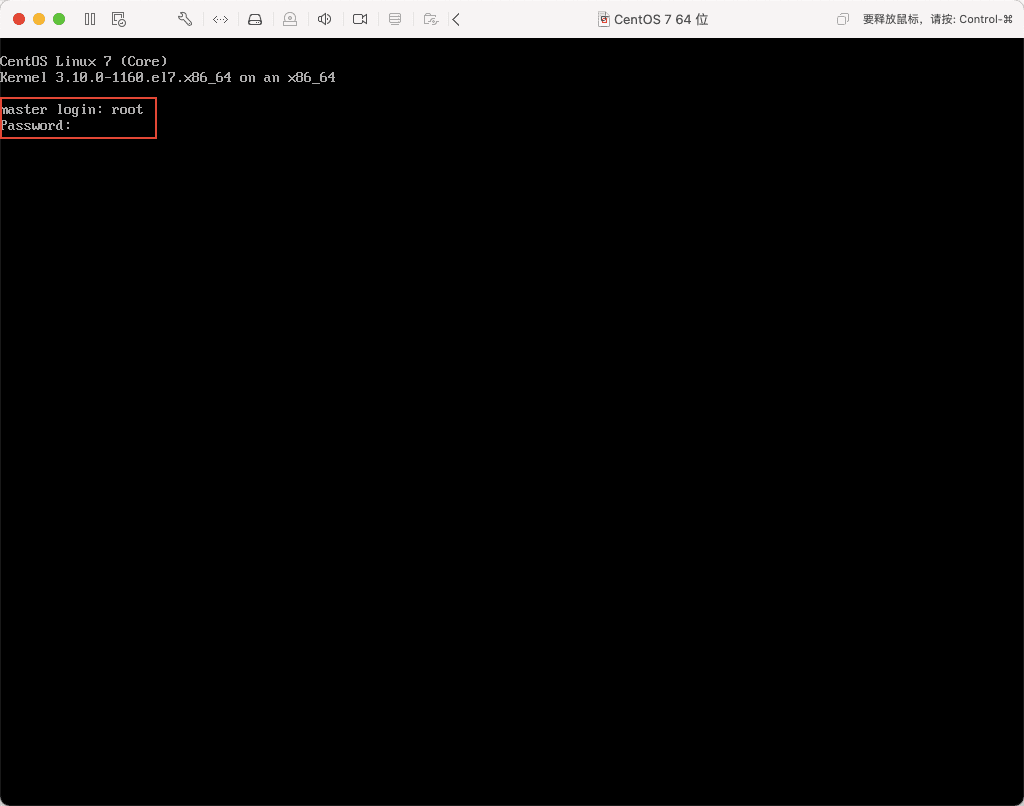
25)当出现下图所示,则表示安装成功。
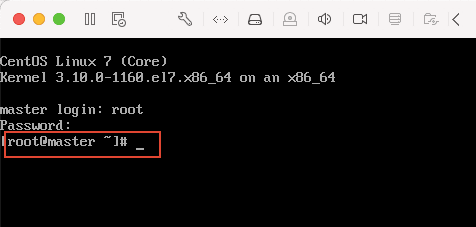
26)然后输入以下命令,测试虚拟机是否与互联网相连。
ping www.baidu.com
出现如下图所示则表示外网链接成功:
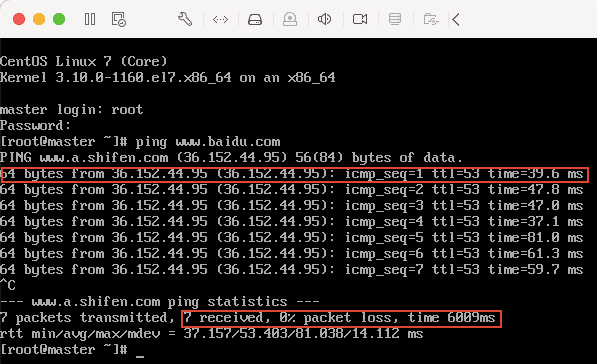
按 ctrl + c 结束 ping 命令。
27)至此,CentOS 安装成功。
配置 CentOS 7
1)现在是联网状态,最好更新一下 yum 源,运行命令 yum -y update
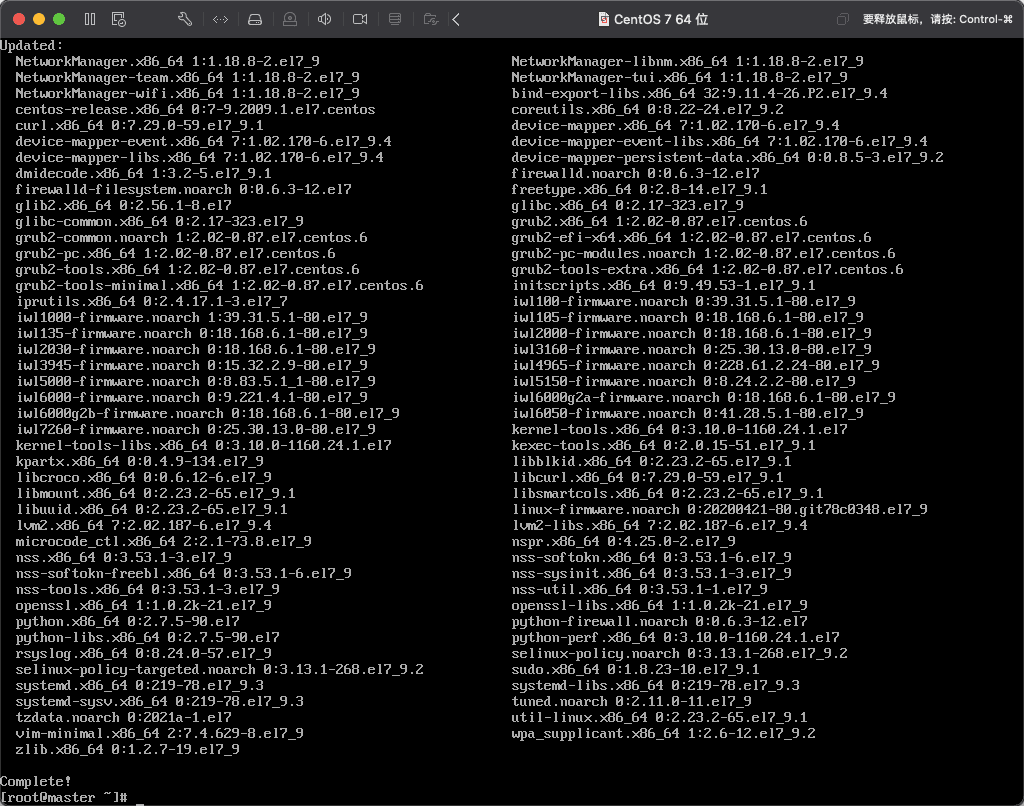
2)当看到 complete 提示信息时表明 yum 更新成功,这些都属于刚安装 Linux 系统的常规操作。如下图所示:
3)接下来关闭系统防火墙,不要担心,现在系统不再公网上,关闭防火墙一般也是不会被黑进来的,放心大胆的关闭吧,而且 Hadoop 集群间后面通信过程中也是要求关掉防火墙的,局域网内通信没必要开防火墙。
先输入临时关闭防火墙的命令,将当前系统的防火墙关闭,然后再输入永久关闭防火墙命令,这个是防止重启系统防火墙自动开启。
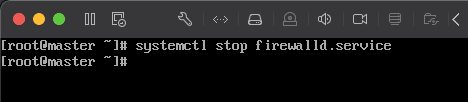
- 临时关闭防火墙
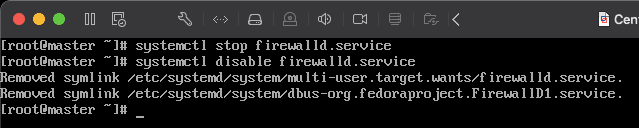
systemctl stop firewalld.service - 永久关闭防火墙
systemctl disable firewalld.service
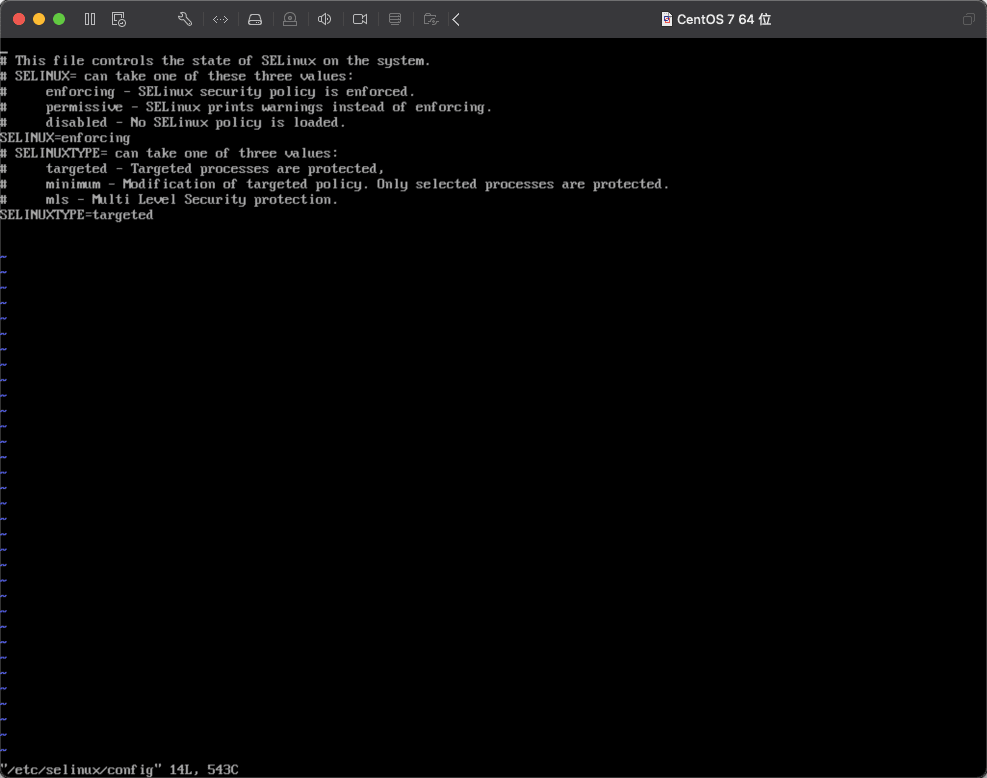
4)接着关闭 Linux 系统安全内核 SELinux。输入命令 vi /etc/selinux/config ,进入编辑 selinux 的配置文件。
💡 这里作为补充,说明一下 vi/vim 命令,vi 是编辑文本的命令,后面跟文本的路径,这条命令的意思是在终端中编辑 selinux 下的 config 文件,回车后会看到如下图所示页面。
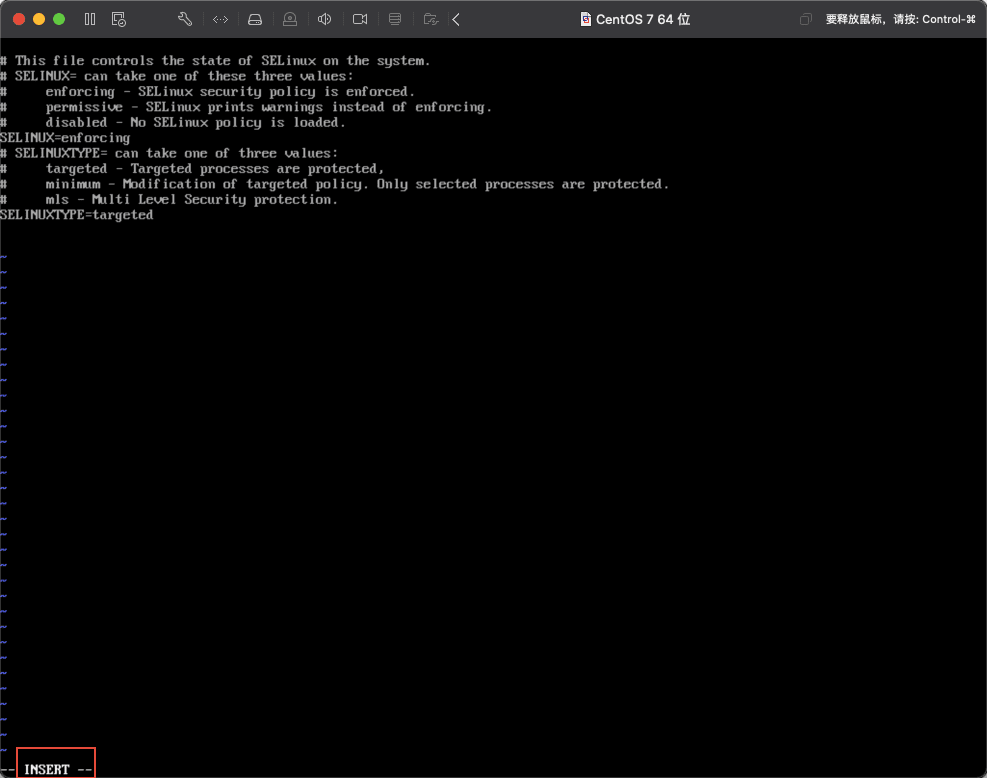
目前是查看状态不能编辑,按下键盘上的字母键i,才会进入编辑模式,如下图所示,(左下角会提示当前为 INSERT 状态,表明可修改内容):
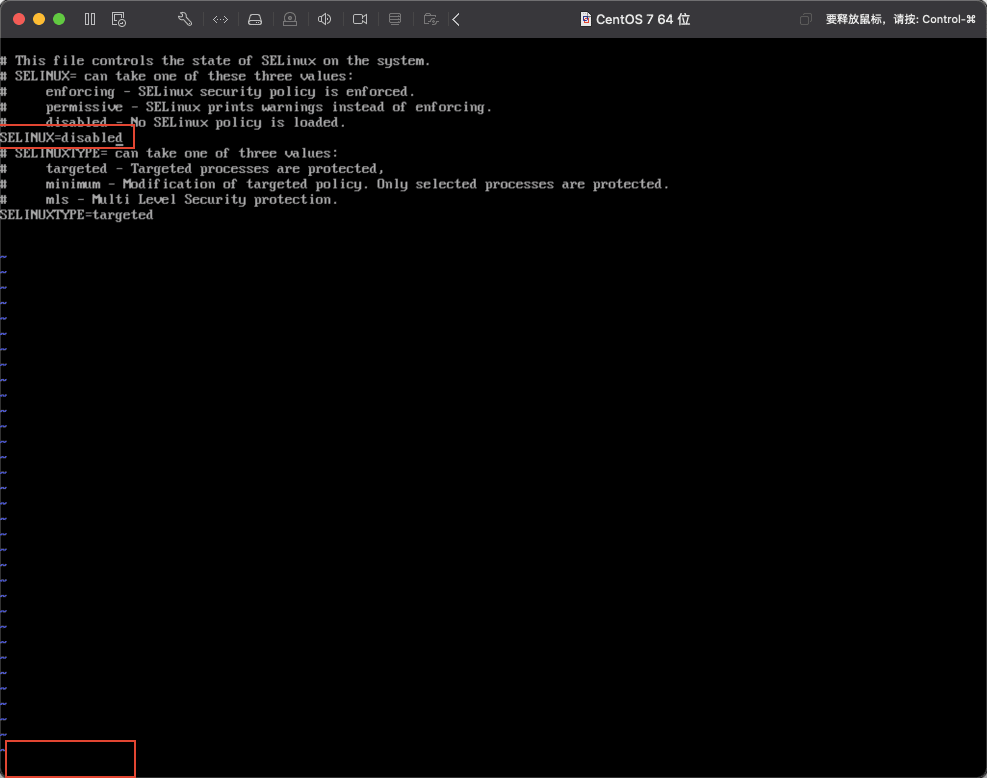
找到SELINUX=enforcing这一行,将=后面的enforcing修改为disabled。然后按下键盘的esc键,如下图所示:
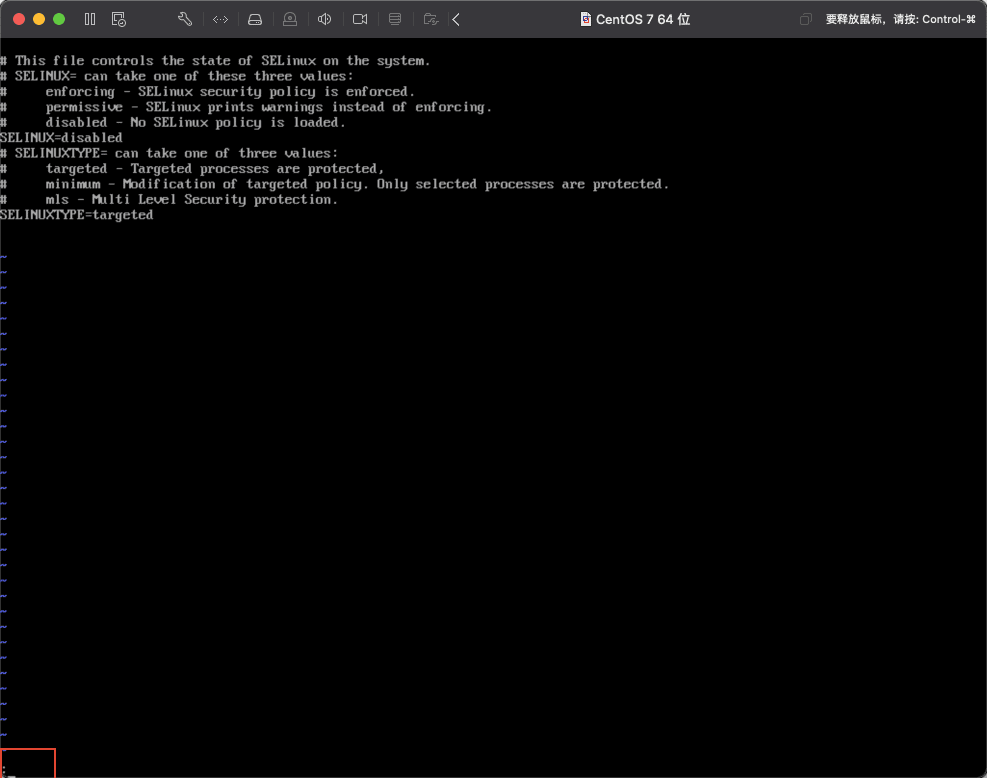
注意当按下 esc 键后,左下角的insert会消失,然后按下键盘的:键,进入指令状态,如下图所示:
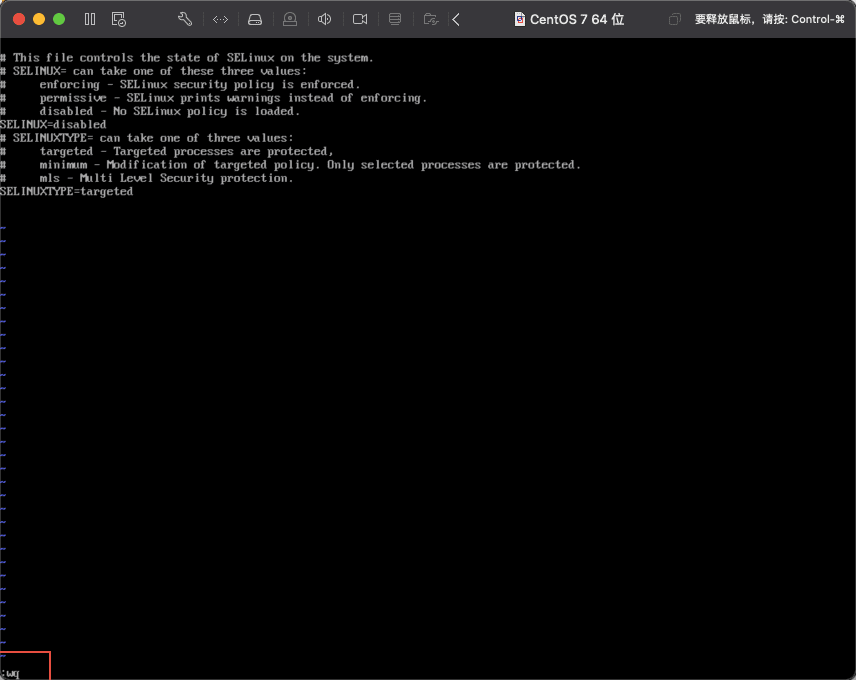
会发现左下角有:显示,证明现在是指令状态,然后输入wq,w指令表示写入文件,q表示退出vi编辑模式,如下图所示:
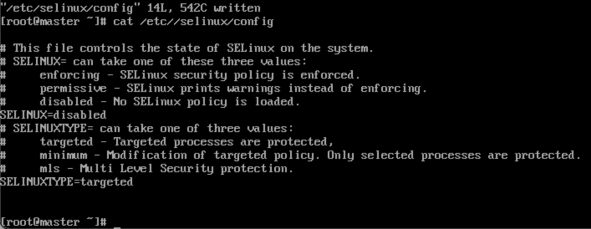
然后按回车,执行刚刚的指令,就回到了初始的命令界面,然后我们检查一下刚才的操作,输入cat /etc/selinux/config命令,查看配置文件是否被正常修改,如下图所示。(养成编辑后就检查的习惯后面会省很多事)
5)输入 reboot 回车重启系统,使以上命令生效。
6)重启后输入 /usr/sbin/sestatus -v 查看 SELinux 是否被禁用。
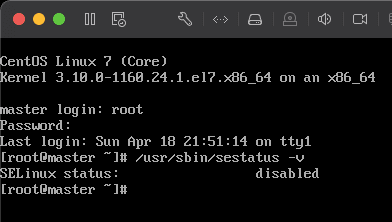
7)输入 yum install vim -y 安装 vim 编辑器,这个和 vi 命令一样,是 vi 命令的增强版,有语法高亮功能,对后面修改 Hadoop 配置会有所帮助。
8)修改 hosts 文件,将后面会配置的虚拟机的 ip 先添加到 hosts 文件中。输入 vim /etc/hosts 编辑 hosts 文件
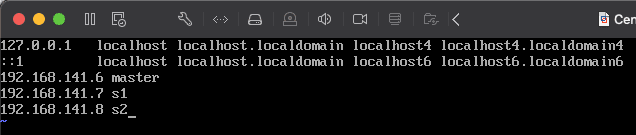 这里的 ip 地址要和之前安装虚拟机时拍照所得的 ip 的网段要一致,第一个 master 主机为当前虚拟机的 ip,后面的 s1,s2 分别在 ip 地址的末尾加 1,我这里 master 的 ip 就是安装虚拟机时拍照所记录的 ip,按照当时的 ip 配置 master 即可,然后将 s1,s2 的 ip 也添加到 hosts 文件中,我这里分别是
这里的 ip 地址要和之前安装虚拟机时拍照所得的 ip 的网段要一致,第一个 master 主机为当前虚拟机的 ip,后面的 s1,s2 分别在 ip 地址的末尾加 1,我这里 master 的 ip 就是安装虚拟机时拍照所记录的 ip,按照当时的 ip 配置 master 即可,然后将 s1,s2 的 ip 也添加到 hosts 文件中,我这里分别是 .7 和 .8 。前面的 192.168.141 要和 master 主机相同,这样 3 台主机才会在同一个网段内,才能 ping 通。修改完成后,保存退出。
9)新建 Hadooptools 文件夹,后面所有文件均在该文件夹下存放。在 root 用户根目录新建 Hadooptools 文件夹,依次输入以下命令:cd /root``mkdir Hadooptools``cd Hadooptools
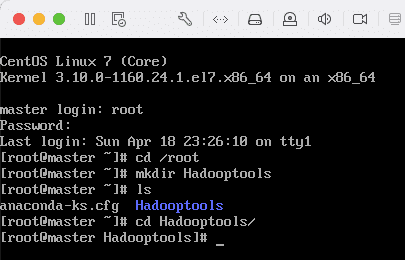
10)下载本文开始所提供的百度网盘资料
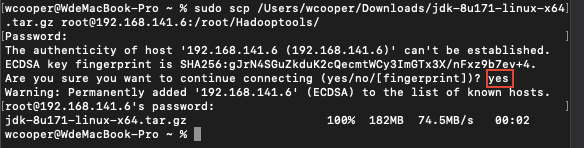
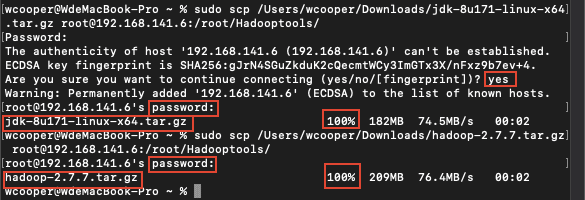
11)通过 mac 自带的 terminal 上传到服务器打开 Mac 终端,然后输入以下命令,注意路径和 ip 换成自己的
sudo scp /Users/wcooper/Downloads/jdk-8u171-linux-x64.tar.gz root@192.168.141.6:/root/Hadooptools/
sudo scp /Users/wcooper/Downloads/jdk-8u171-linux-x64.tar.gz root@192.168.141.6:/root/Hadooptools/
这里上传 Hadoop 和 jdk 的安装包,scp 命令用法如下:
scp local_file remote_username@remote_ip:remote_folder
local_file 在这里就是下载到的文件路径,直接将文件拖到终端里就会自动填入路径,我这里是在 Downloads文件夹内。后面接着远程主机要连接的用户名和 IP 地址或主机名,因为我们这里没有在 mac 的 host 文件中配置远程主机,所以直接用 ip 即可,用户名和 ip 之间用@隔开,然后冒号后跟上要存在远程主机的那个目录的路径即可,这里统一用 /root/Hadooptools/在执行命令中,会问到是否连接,输入 yes 同意后回车即可,然后输入 root 用户的密码回车,同样这里的密码输入也是不显示的,当看到进度变为 100%,即表示上传成功,如下图:
12)到虚拟机,cd 到 Hadooptools 文件夹,然后查看是否有刚刚上传的文件:cd /root/Hadooptools``ls
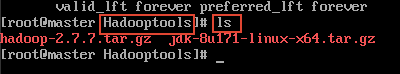
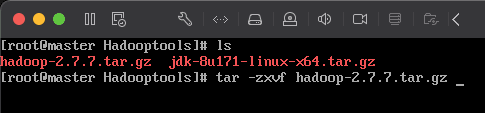
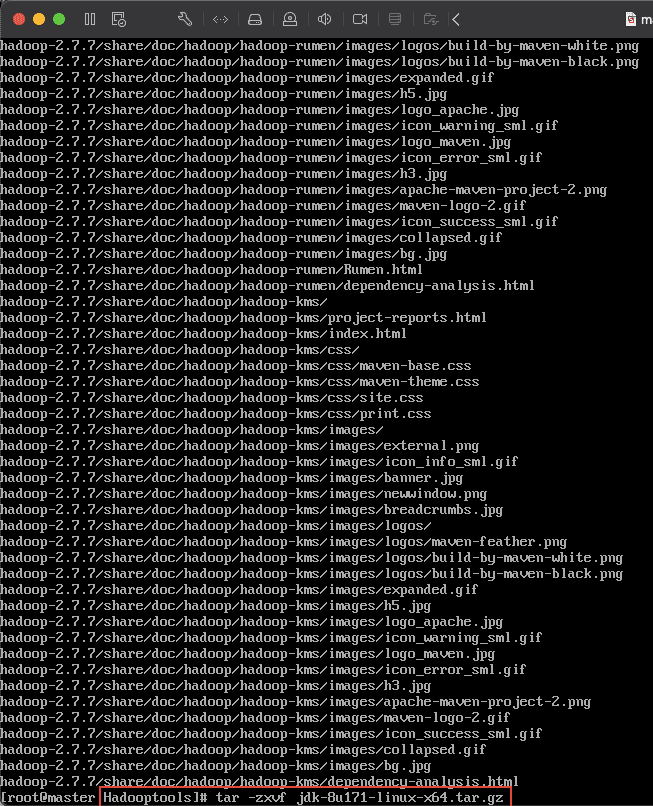
13)分别解压 2 个压缩包:tar -zxvf hadoop-2.7.7.tar.gz``tar -zxvf jdk-8u171-linux-x64.tar.gz
14)安装 jdk 先 cd 到 root 用户根目录 cd ~
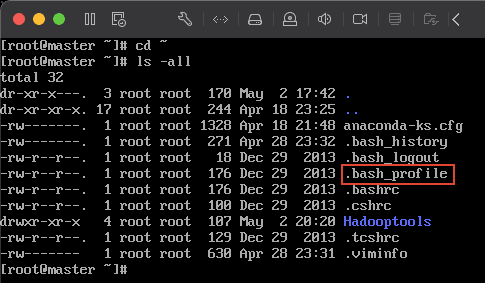 然后用
然后用 vim 编辑 .bash_profile``vim .bash_profile
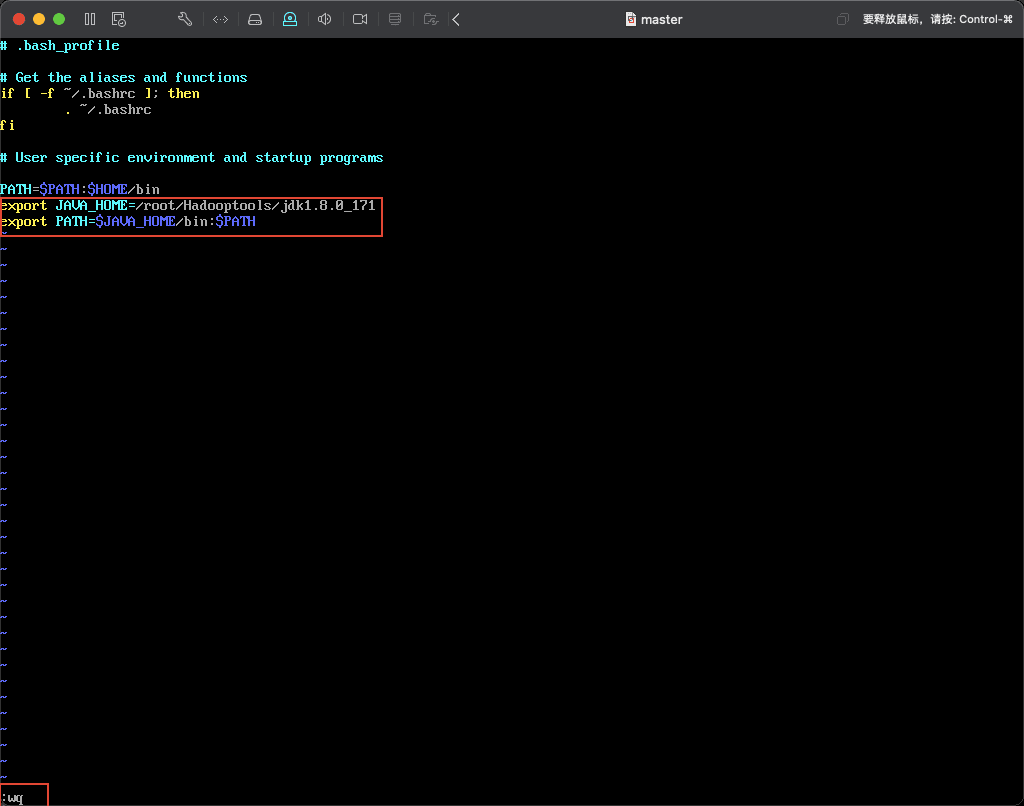
 将以下内容添加到文件中:
将以下内容添加到文件中:
export JAVA_HOME=/root/Hadooptools/jdk1.8.0_171
export PATH=$JAVA_HOME/bin:$PATH
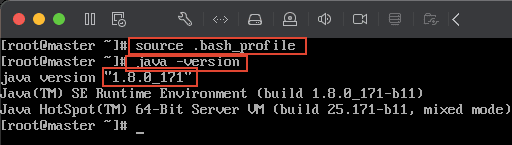
保存后,输入以下命令使修改的配置生效:source .bash_profile然后输入 java -version 查看 java 版本,检验安装是否成功,如果能出现下图所示,即表示配置成功。
15)至此 centos 7 配置完毕,准备关机复制虚拟机,组成 3 台虚拟机集群。输入 shutdown now 立即关闭虚拟机
复制虚拟机,完善 ip 与主机名配置
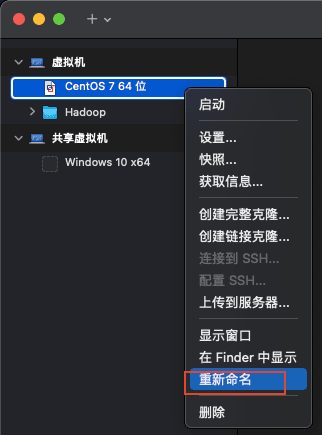
1)将我们目前的虚拟机名字修改为 master 方便识别,如下图所示(右键点击虚拟机名称,然后点击重命名):
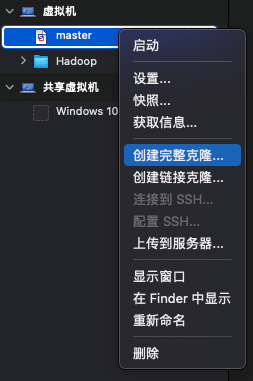
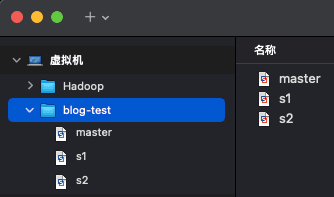
2)之后右键点击 master 然后点 创建完整克隆 ,复制我们当前的虚拟机 2 次,将复制得到的虚拟机分别命名为 s1, s2 ,如下图所示:
3)将 3 台虚拟机依次启动,然后修改 ip 先进入 s1 虚拟机,然后输入以下命令,编辑网络配置文件:vim /etc/sysconfig/network-scripts/ifcfg-ens33将其 ip 设置为 192.168.141.7 ,保存后,输入 service network restart 使配置生效。
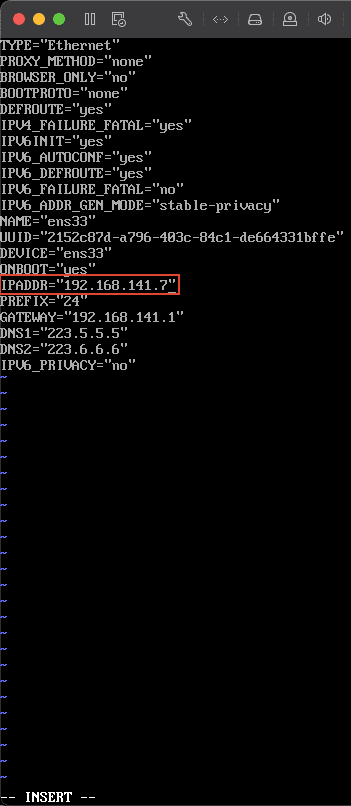 同样的命令配置好 s2,配置其 ip 地址为
同样的命令配置好 s2,配置其 ip 地址为 192.168.141.8 ,然后保存,输入命令使配置生效。这里的 ip 地址与安装 Linux 系统时拍照记录的 ip 地址有关,前面的 192.168.141 与装系统时的 ip 地址完全一致,后面一位和上文配置 centos7里的第 8 小步一致,配置的 hosts 文件保持一致。
4)接下来修改主机名,输入以下命令:S1: hostnamectl set-hostname s1S2: hostnamectl set-hostname s2完成后分别在 s1,s2 做用户登出,输入命令:logout然后再输入用户名 root,密码,登入系统,这时会看到如下图所示位置已经变成了 root@s1,s2。说明主机名修改成功。
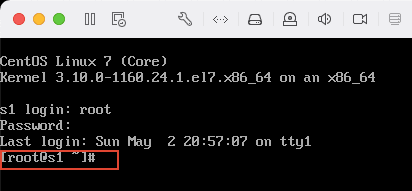
5)分别测试是否能 ping 通在 master 主机上分别输入以下命令:
ping master
ping s1
ping s2
如果能正确收到数据包,说明 master 与 s1,s2 能正常连接接下来依次在 s1,s2 上分别做以上验证,保证能够正常 ping 通即可。
使用 termius 连接 3 台虚拟机
1)打开 termius,选择新建 group

2)填写 group 名,这里以 hadoop 集群为例,然后点击 save 保存。
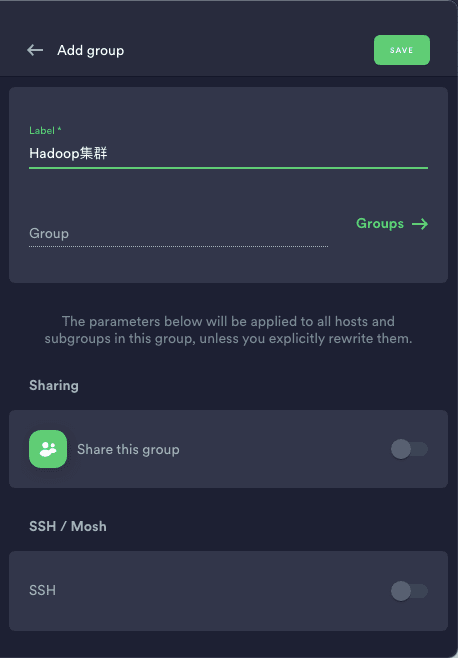
3)双击进入刚刚新建的 group

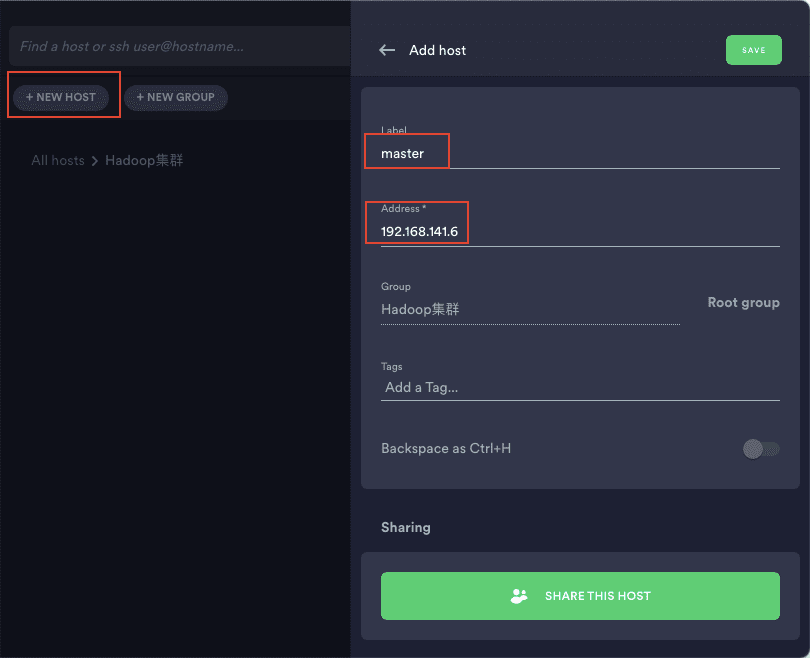
4)点击新建 host,依次新建 master、s1、s2,设置好 ip 并输入用户名密码即可,然后点击 save 保存
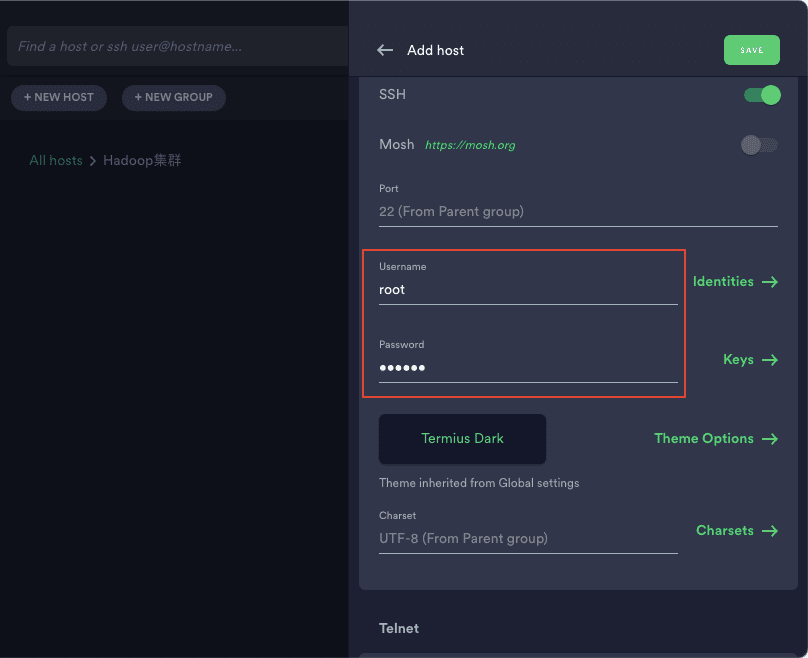
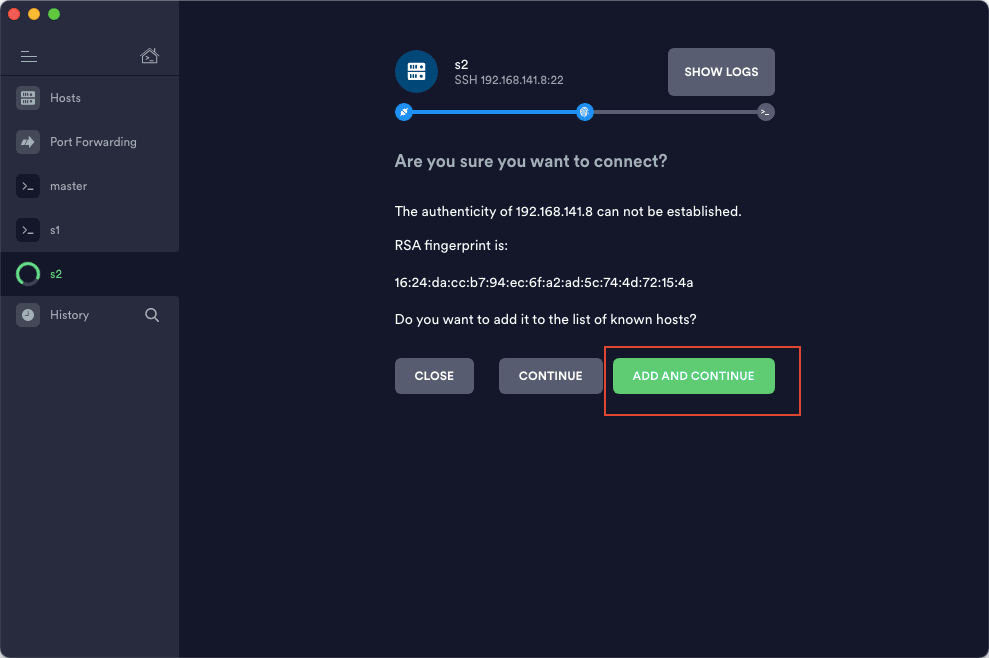
5)双击新建的 host,然后选择 add and continue 即可成功连接到虚拟机
6)成功连接 3 台虚拟机后,命令就可以直接在这里输入,不必再从虚拟机的页面里输入了,但是虚拟机要保持开机状态,关机就没办法连接了。
制作免密码登陆
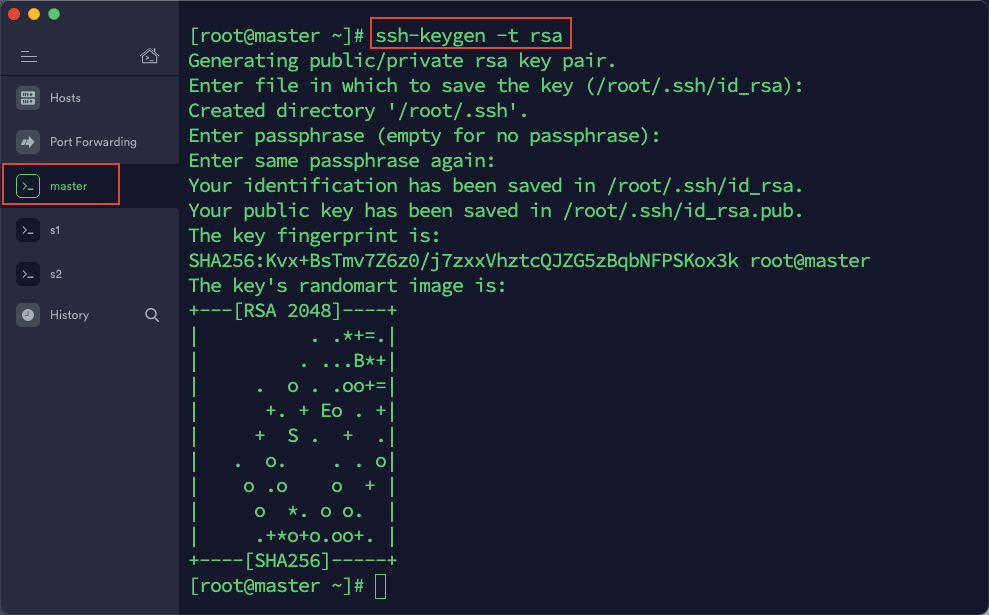
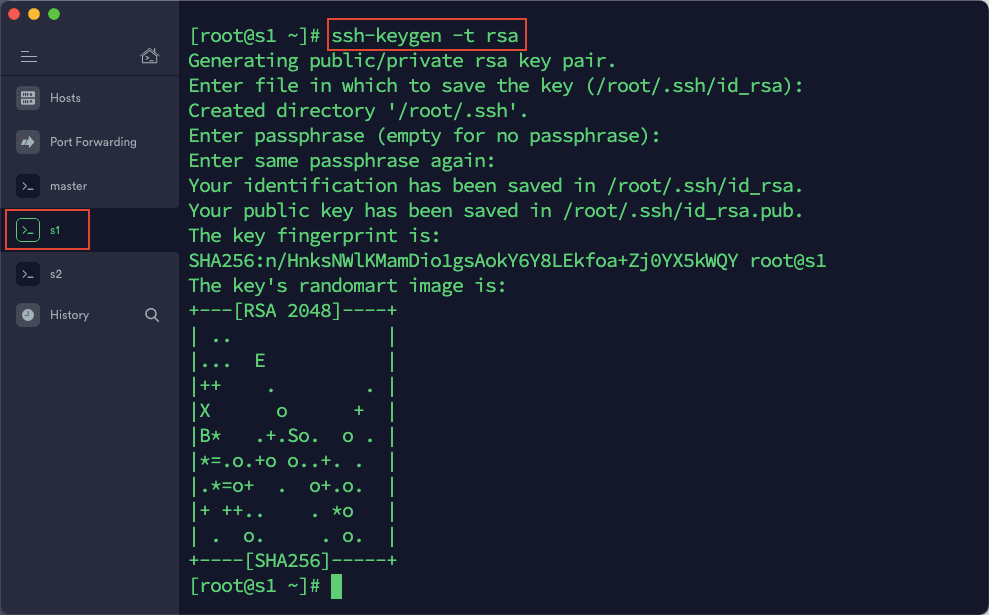
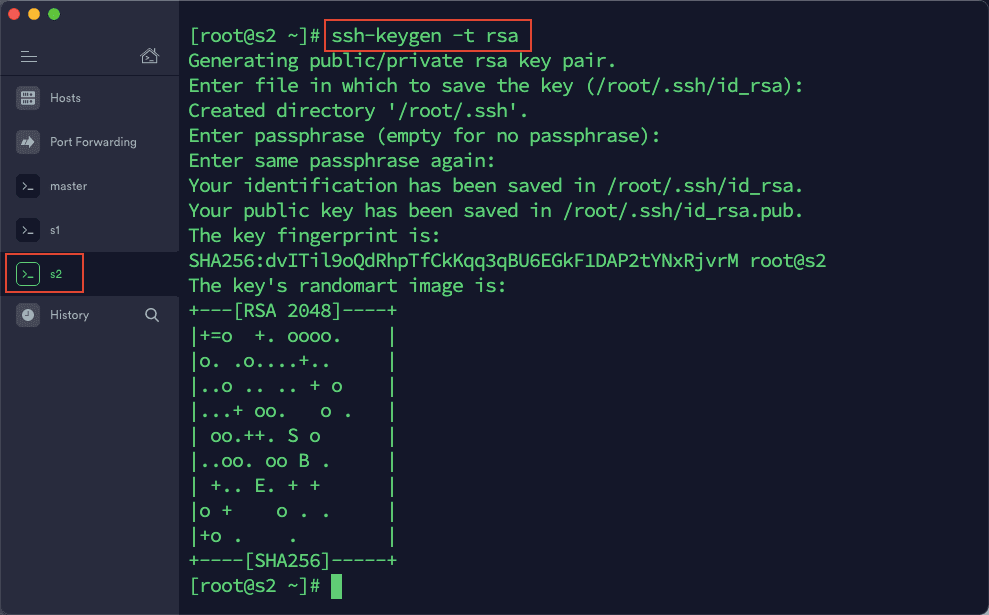
1)在 termius 中打开与三台虚拟机的连接,在 master 中输入以下命令:ssh-keygen -t rsa然后一路按回车,直到命令运行结束。同样操作,在 s1,s2 中依次执行一遍。
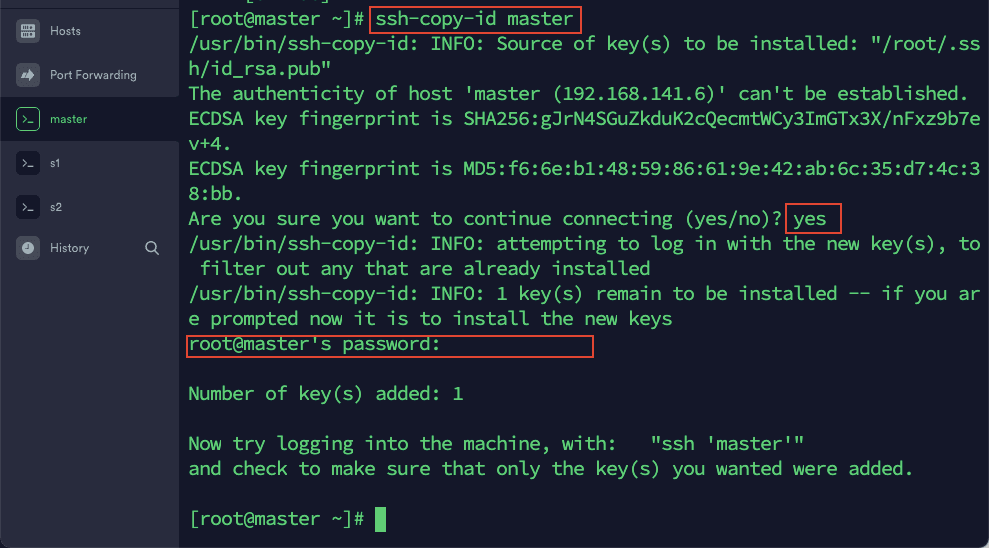
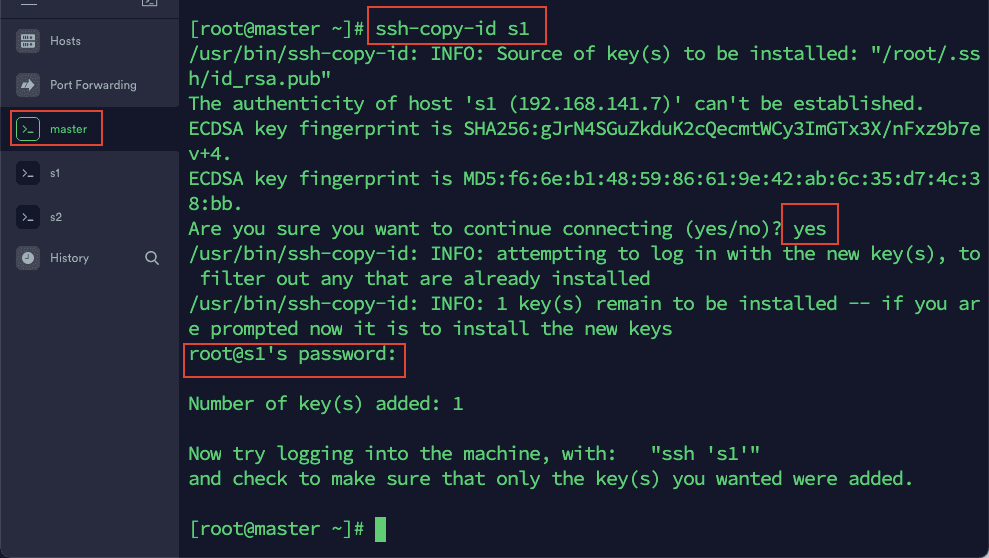
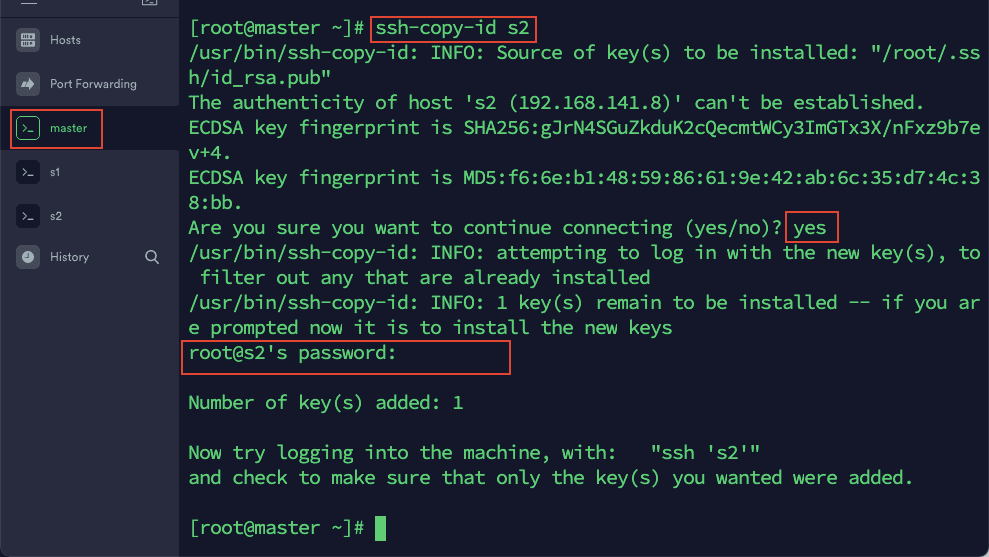
2)在 master 依次输入以下命令:
ssh-copy-id master
ssh-copy-id s1
ssh-copy-id s2
然后根据提示输入 master,s1,s2 的密码。这里是为了实现 master 通过 ssh 登陆 s1,s2 和自己免密。
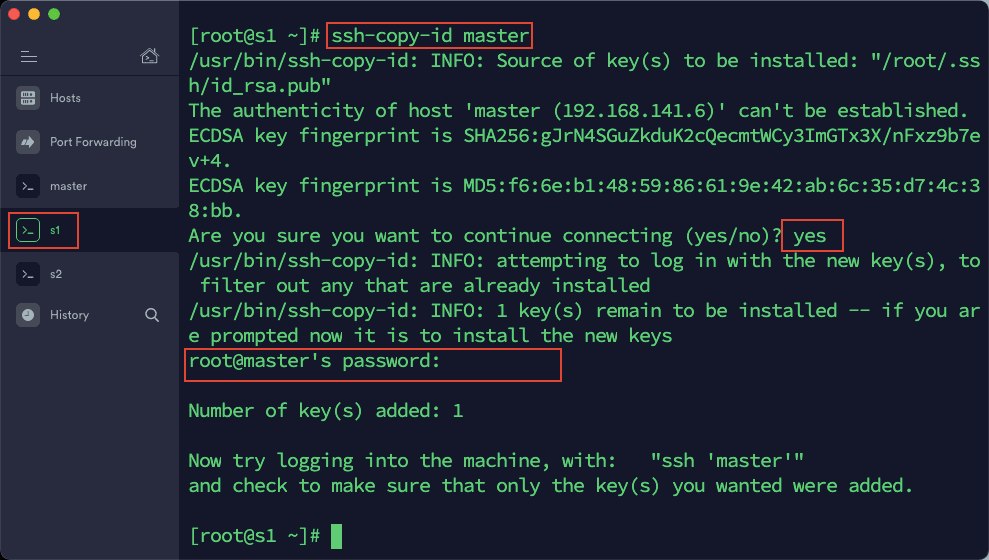
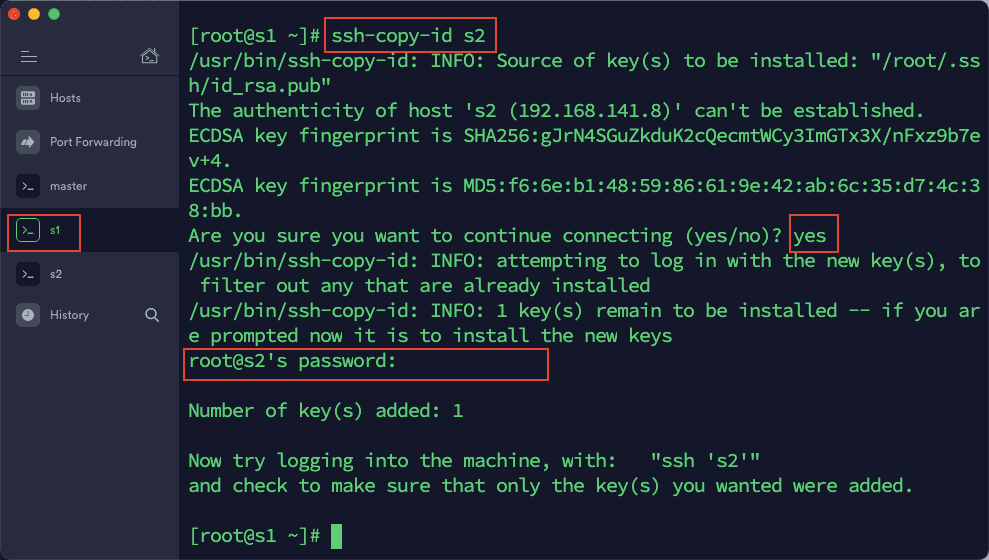
3)在 s1 中依次输入以下命令:
ssh-copy-id master
ssh-copy-id s2
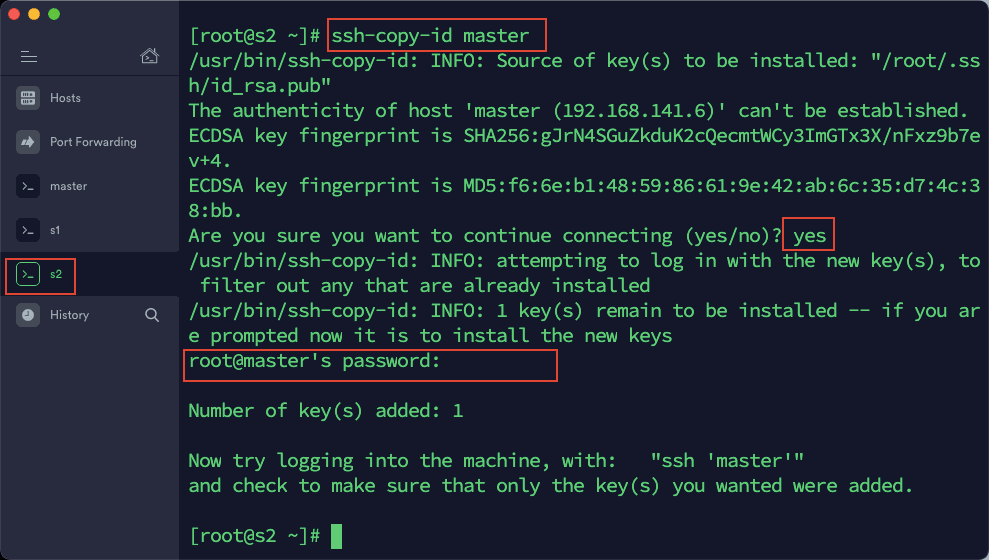
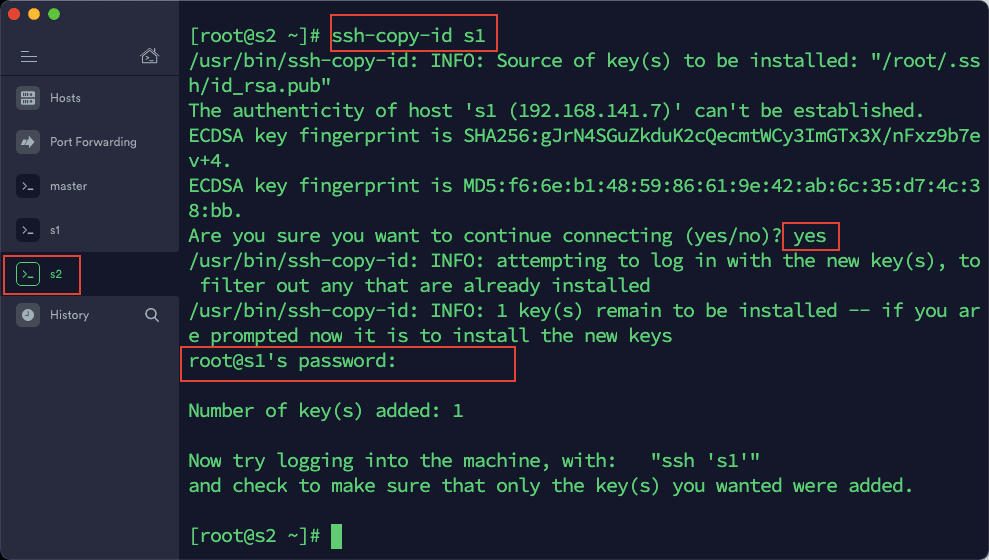
4)在 s2 中依次输入以下命令:
ssh-copy-id master
ssh-copy-id s1
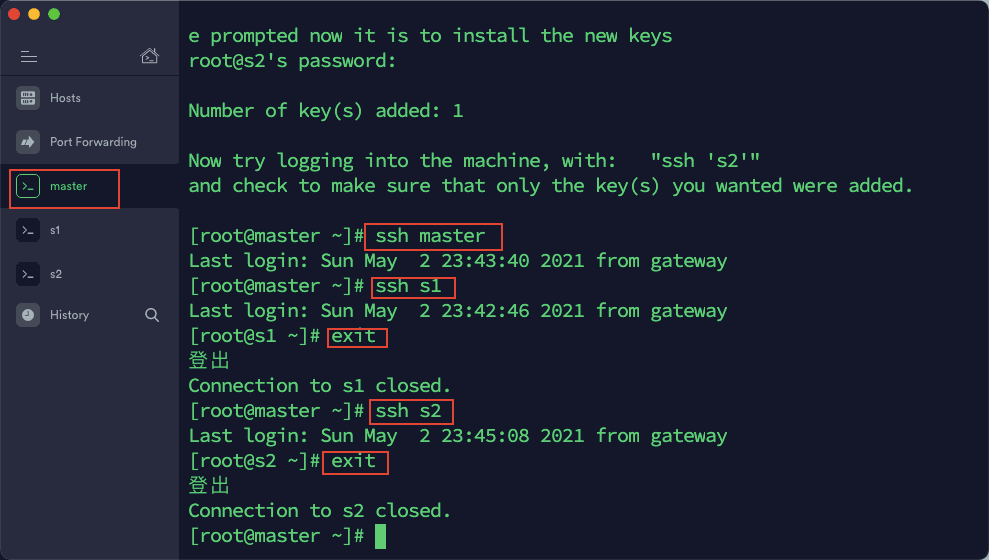
5)通过 ssh 命令测试互相登陆,如果相互登陆都不需要密码的话,表示免密码登陆设置成功。测试命令:ssh 主机名
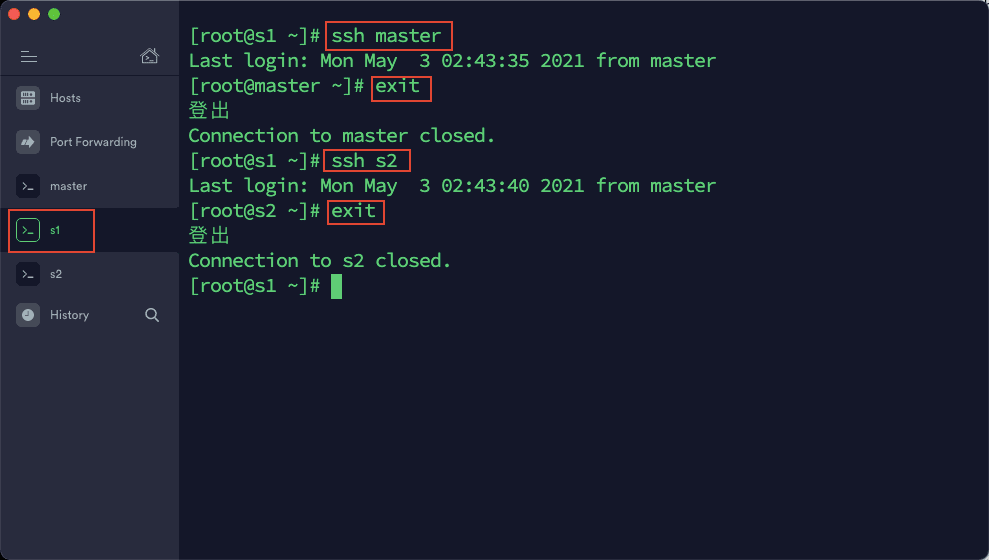
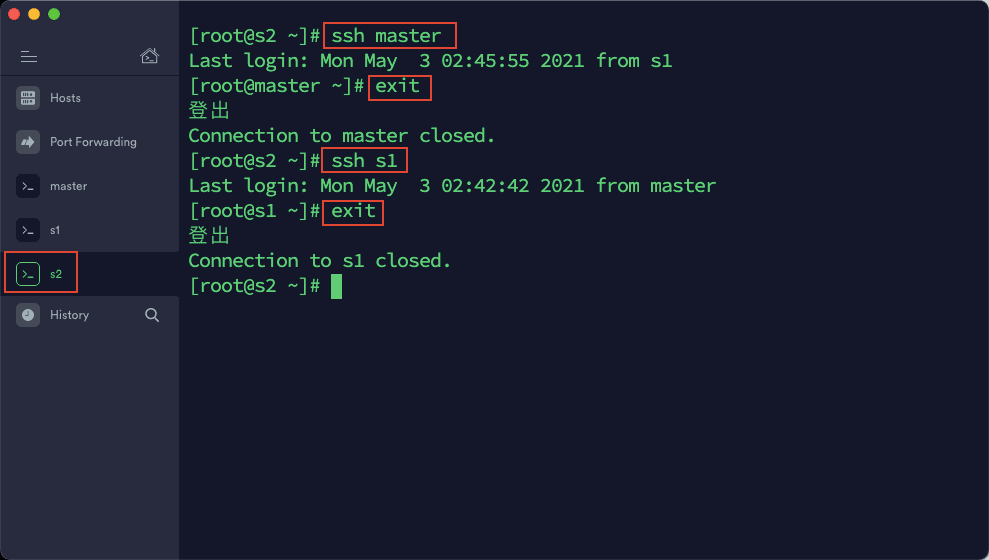
配置时间同步
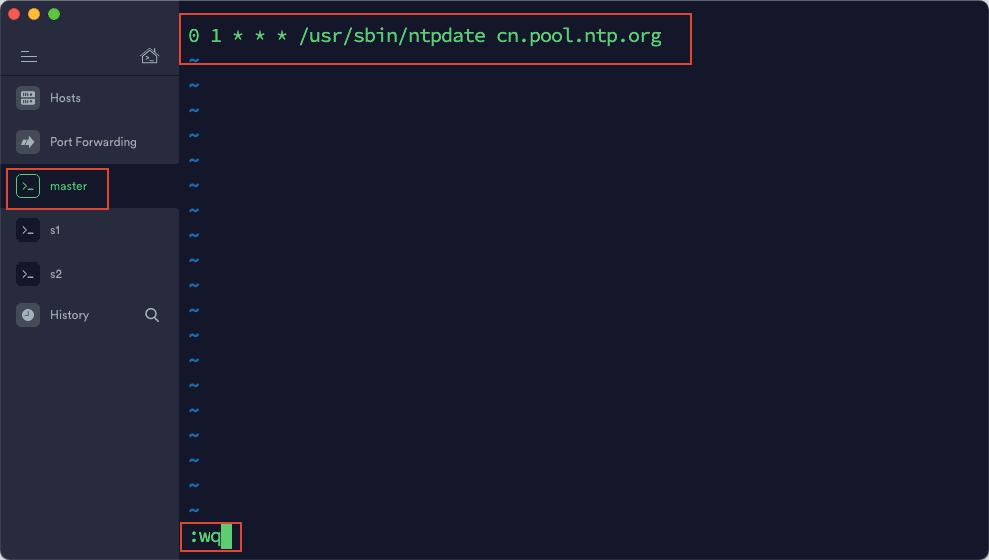
1)在 master 中,输入命令:crontab -e
2)输入:0 1 * * * /usr/sbin/ntpdate cn.pool.ntp.org ,然后保存退出。
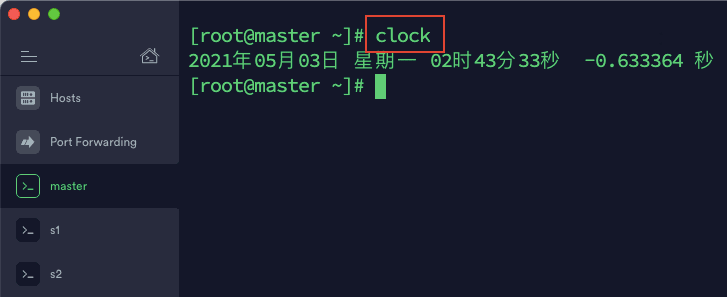
3)输入命令 clock 检查时间是否正确
4)其余 2 台虚拟机重复上述操作
配置 Hadoop
以下修改操作全部在 master 上进行,也就是只修改 master 里的文件,然后将 master 上的文件全部复制到 s1,s2 上即可。
修改 hadoop-env.sh
1)cd 到 hadoop-2.7.7 文件夹下 cd /root/Hadooptools/hadoop-2.7.7/etc/hadoop/
2)输入命令,修改 hadoop-env.sh vim hadoop-env.sh 将原来 export JAVA_HOME 那一项修改为以下值(指明本机 JAVA_HOME 的路径),然后 wq 保存退出:
# The java implementation to use.
export JAVA_HOME=/root/Hadooptools/jdk1.8.0_171
修改 yarn-env.sh
1)cd 到 hadoop-2.7.7 文件夹下 cd /root/Hadooptools/hadoop-2.7.7/etc/hadoop/
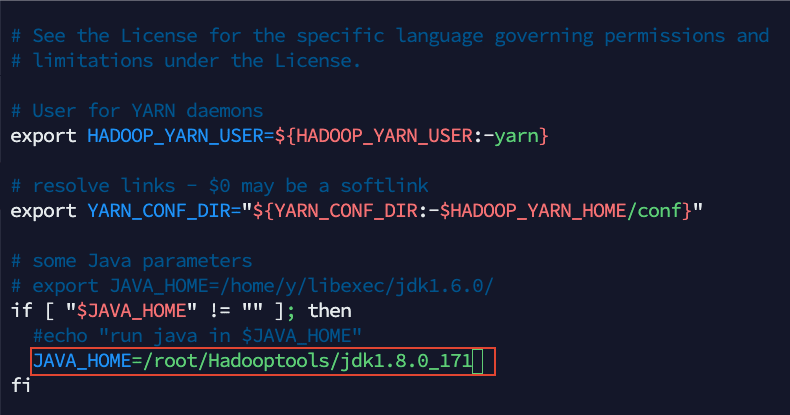
2)输入命令,修改 yarn-env.sh vim yarn-env.sh 同样修改 JAVA_HOME ,然后 wq 保存退出
# some Java parameters
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=/root/Hadooptools/jdk1.8.0_171
修改 core-site.xml
1)cd 到 hadoop-2.7.7 文件夹下 cd /root/Hadooptools/hadoop-2.7.7/etc/hadoop/
2)输入命令,修改 core-site.xml vim core-site.xml
3)将以下内容复制粘贴到文件中,然后保存退出
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
<description>配置NameNode的URL</description>
</property>
<!--用来指定hadoop运行时产生的存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/Hadooptools/hadoop-tmp</value>
</property>
</configuration>
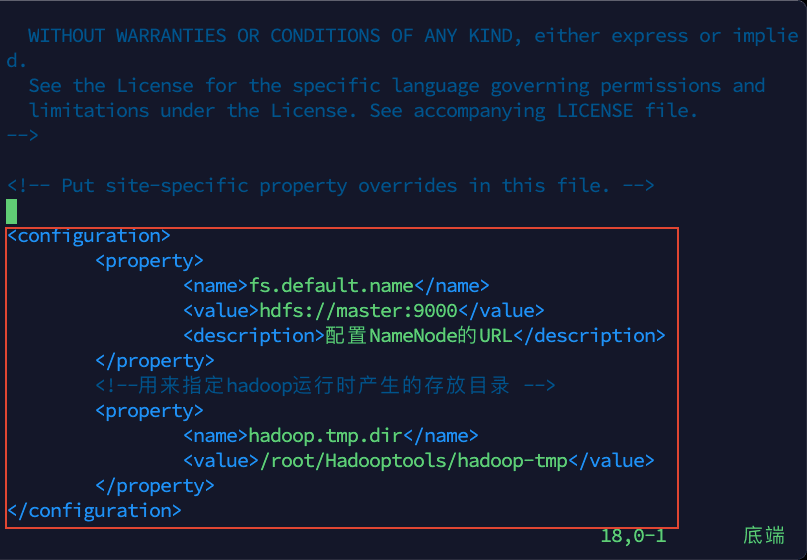
这里将 hadoop 运行时的临时文件存放目录设置为/root/Hadooptools/hadoop-tmp,目前系统中是没有这个目录的,后面需要新建这个目录。
修改 hdfs-site.xml
1)cd 到 hadoop-2.7.7 文件夹下 cd /root/Hadooptools/hadoop-2.7.7/etc/hadoop/
2)输入命令,修改 hdfs-site.xml vim hdfs-site.xml
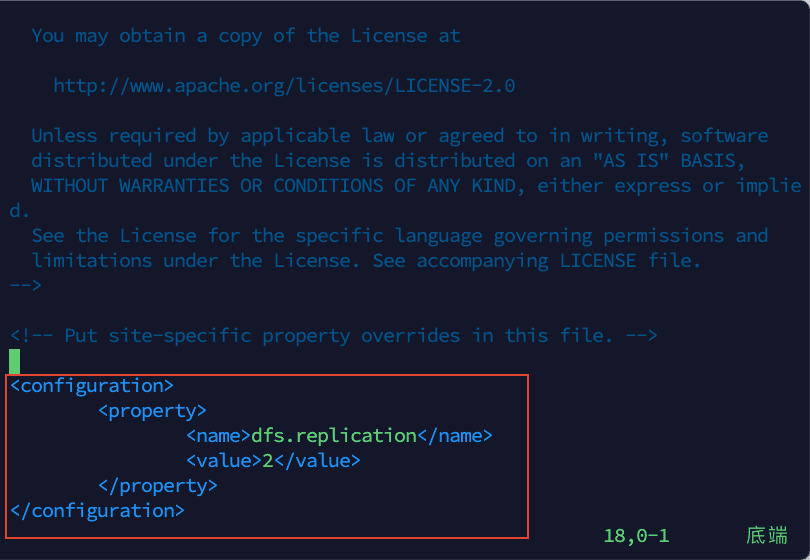
3)将以下内容添加到文件,然后保存退出:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
修改 mapred-site.xml
1)cd 到 hadoop-2.7.7 文件夹下 cd /root/Hadooptools/hadoop-2.7.7/etc/hadoop/
2)输入命令,修改 mapred-site.xml, vim mapred-site.xml
3)将以下内容复制粘贴到文件中,保存退出
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改 yarn-site.xml
1)cd 到 hadoop-2.7.7 文件夹下 cd /root/Hadooptools/hadoop-2.7.7/etc/hadoop/
2)输入命令,修改 yarn-site.xml vim yarn-site.xml
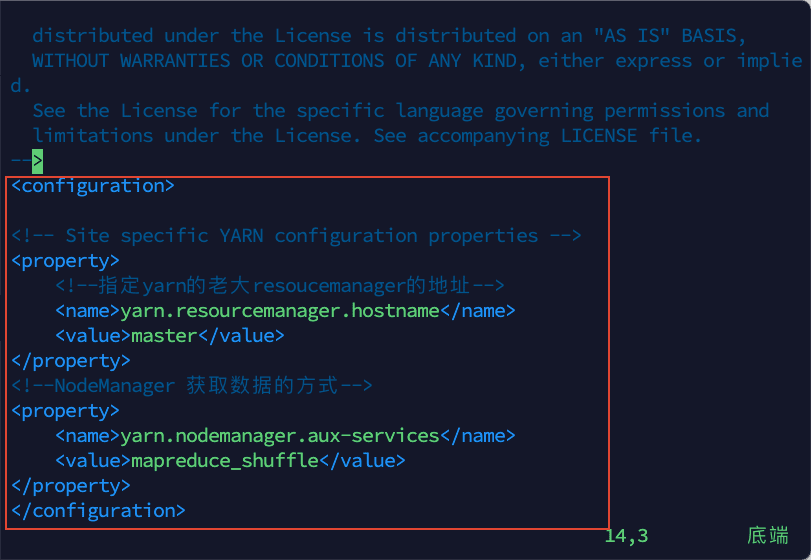
3)将以下内容复制粘贴到文件中:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<!--指定yarn的老大resoucemanager的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!--NodeManager 获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改 slaves
1)cd 到 hadoop-2.7.7 文件夹下 cd /root/Hadooptools/hadoop-2.7.7/etc/hadoop/
2)输入命令,修改 slaves vim slaves复制粘贴以下内容到文件:
master
s1
s2

建立 hadoop-tmp 文件夹
1)cd 到 Hadooptools 文件夹下 cd /root/Hadooptools/
2)输入命令 mkdir hadoop-tmp 新建文件夹
删除 s1,s2 上的 Hadooptools 文件夹
1)依次在 s1,s2 上执行一下命令,千万别删错了,不要删除在 master 上的文件夹:rm -rf /root/Hadooptools/
2)将 master 上的 Hadooptools文件夹复制到 s1,s2 上。依次运行以下命令:
scp -r /root/Hadooptools root@s1:/root/
scp -r /root/Hadooptools root@s2:/root/
配置系统环境变量
1)用 vim 打开系统环境变量配置文件 vim /root/.bash_profile
2)将以下内容添加到文件中
export HADOOP_HOME=/root/Hadooptools/hadoop-2.7.7
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:
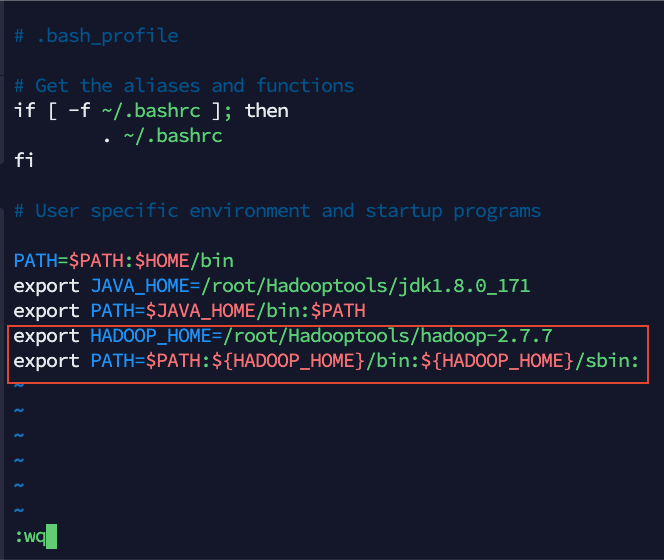
然后执行命令 source /root/.bash_profile 使配置生效。重复上述操作将 s1,s2 虚拟机的环境变量也配置成这样。
3)格式化 hadoop 文件系统
该命令只能在 master 上执行,且只能执行一次,不可多次执行。
hdfs namenode -format
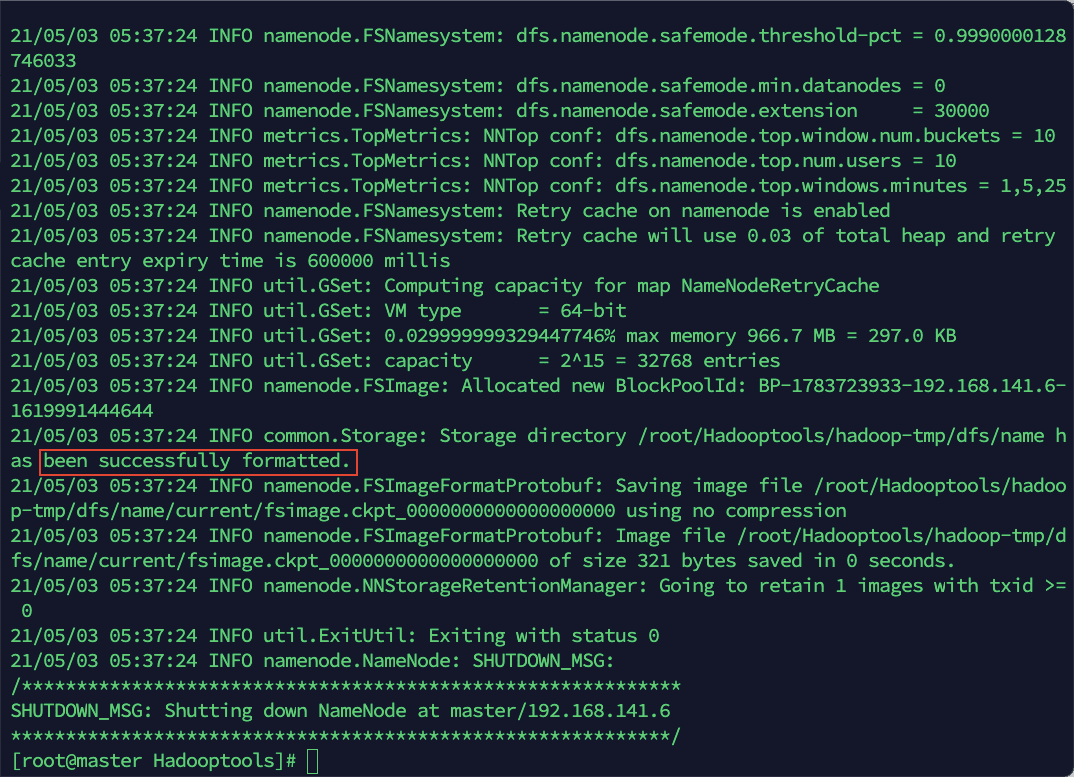
当看到如上图中所示 successfully 提示信息则表示格式化成功。
一行命令启动 Hadoop 集群
1)start-all.sh

2)根据提示信息,输入 yes
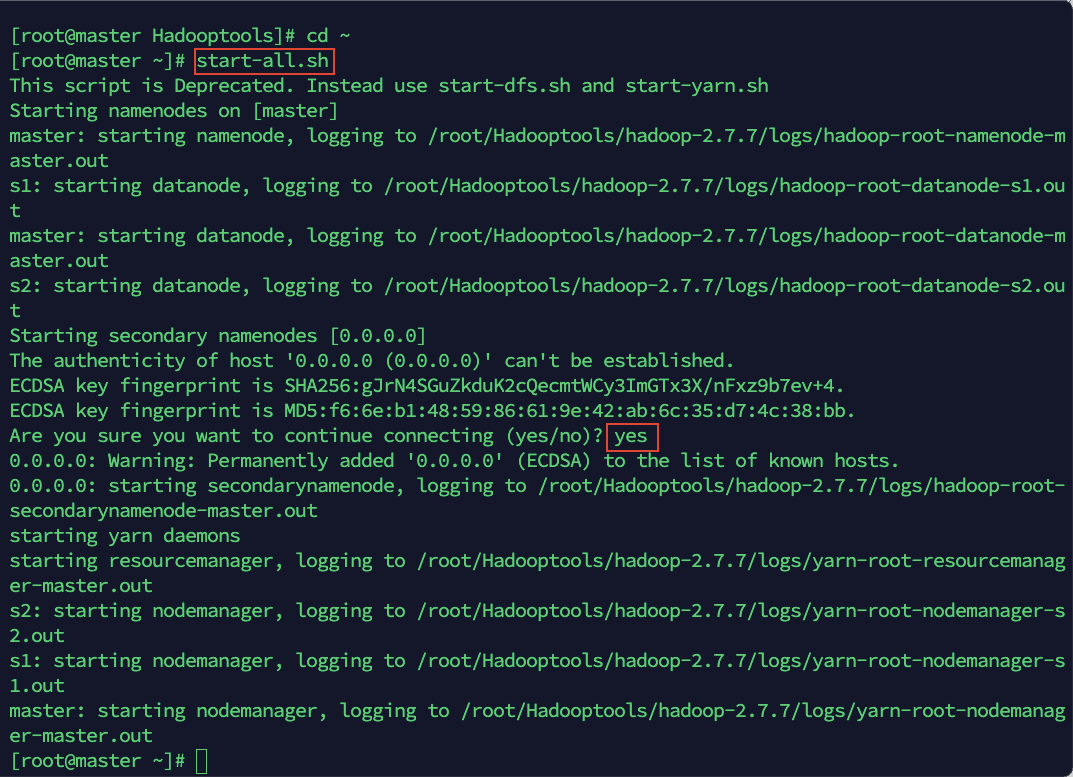
3)用宿主机浏览器访问 http://192.168.141.6:50070 查看启动是否成功。
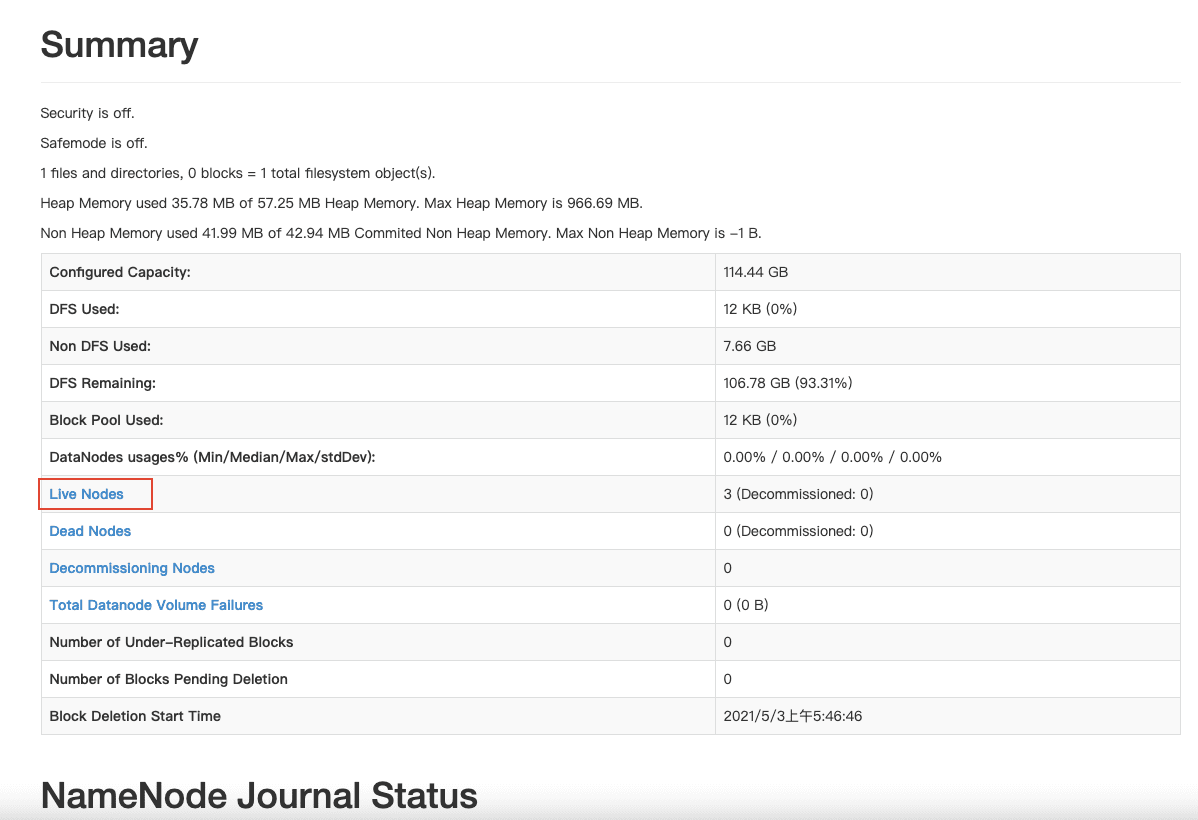
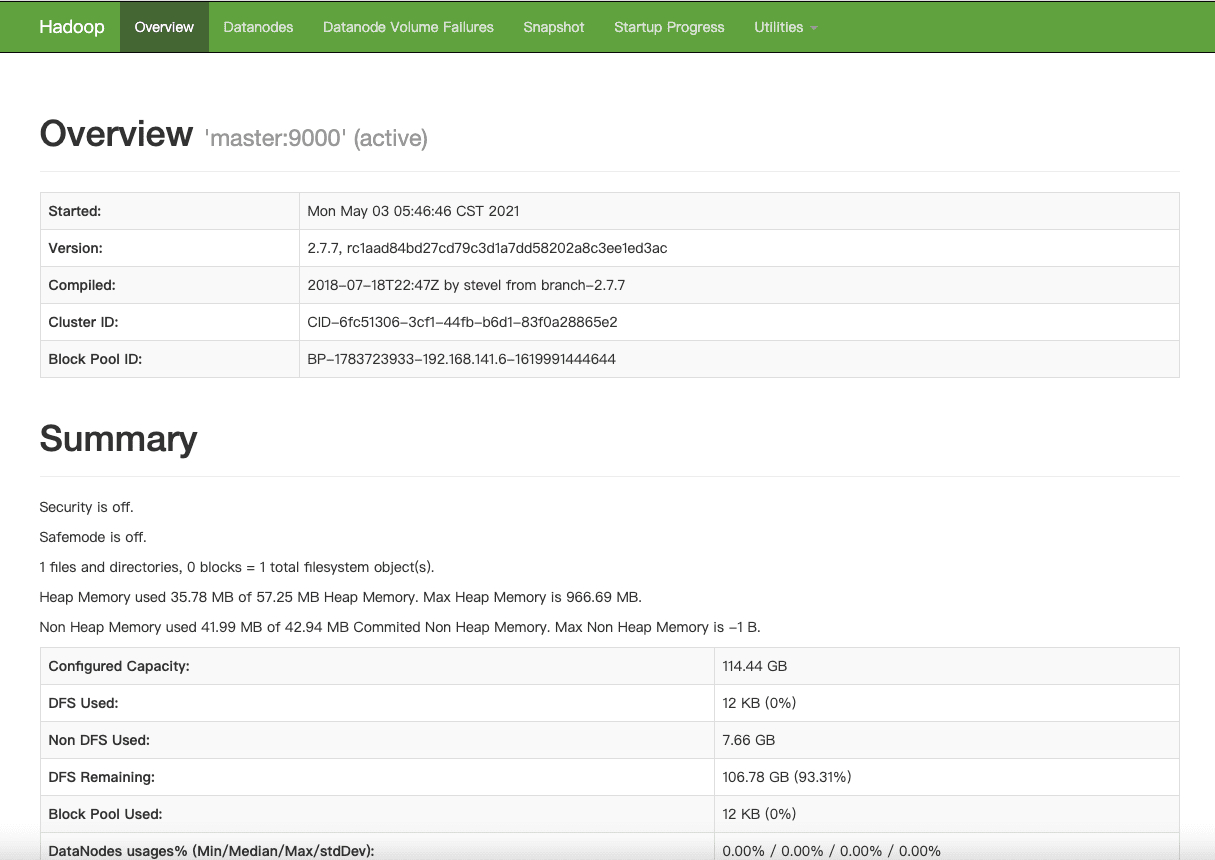 找到网页中的 summary,点开 livenodes 查看现在是否有 3 台节点同时在线,如果不是 3 台,则说明配置有问题,需要重新排错,按照教程前面内容仔细检查,如果显示是 3 台主机在线,则表明配置成功。
找到网页中的 summary,点开 livenodes 查看现在是否有 3 台节点同时在线,如果不是 3 台,则说明配置有问题,需要重新排错,按照教程前面内容仔细检查,如果显示是 3 台主机在线,则表明配置成功。
4)登陆 yarn 的 WebUI http://192.168.141.6:8088/
安装 spark
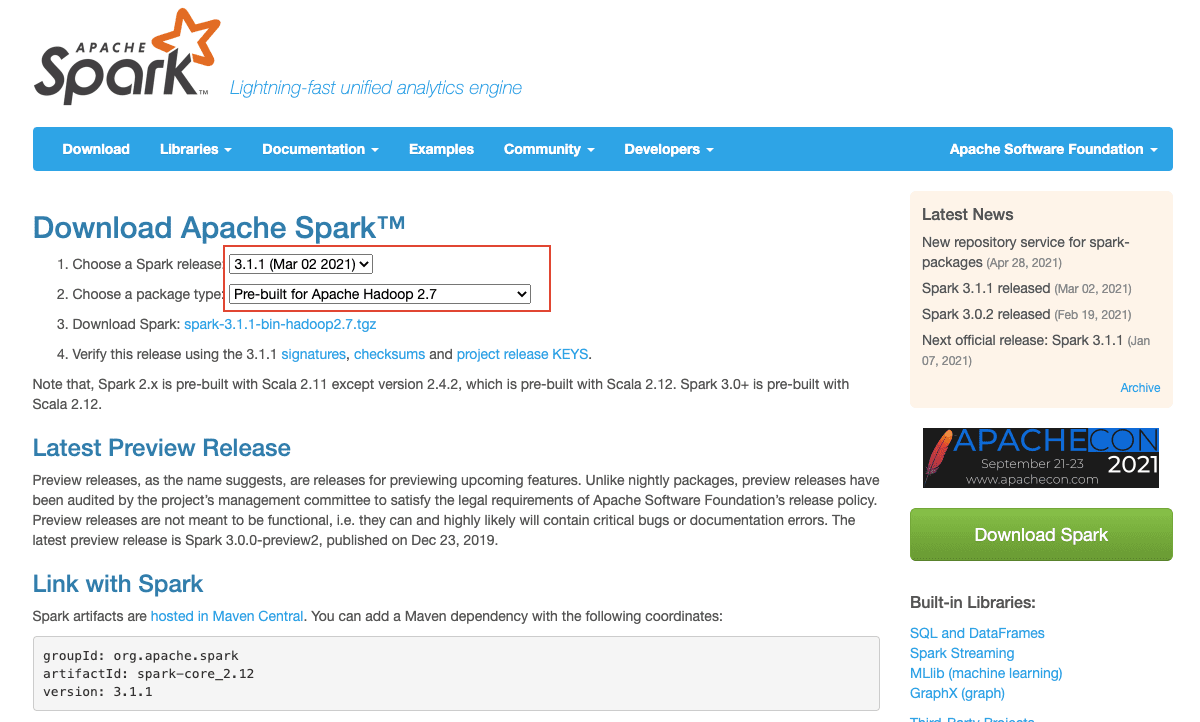
1)登陆 Apache spark 官网下载 spark 地址:http://spark.apache.org/downloads.html选择如下图所示版本进行下载
2)将下载的压缩包上传到 master 主机在 mac 终端中输入:
scp /Users/wcooper/Downloads/spark-3.1.1-bin-hadoop2.7.tgz root@192.168.141.6:/root/Hadooptools/
注意下载路径换成自己的。

3)用 termius 登陆 master 主机,解压刚刚上传的压缩包
- 先 cd 到 Hadooptools 目录
cd /root/Hadooptools - 然后执行解压缩命令
tar -zxvf spark-3.1.1-bin-hadoop2.7.tgz
4)将 spark-3.1.1-bin-hadoop2.7 文件夹名字修改成 spark mv spark-3.1.1-bin-hadoop2.7 spark

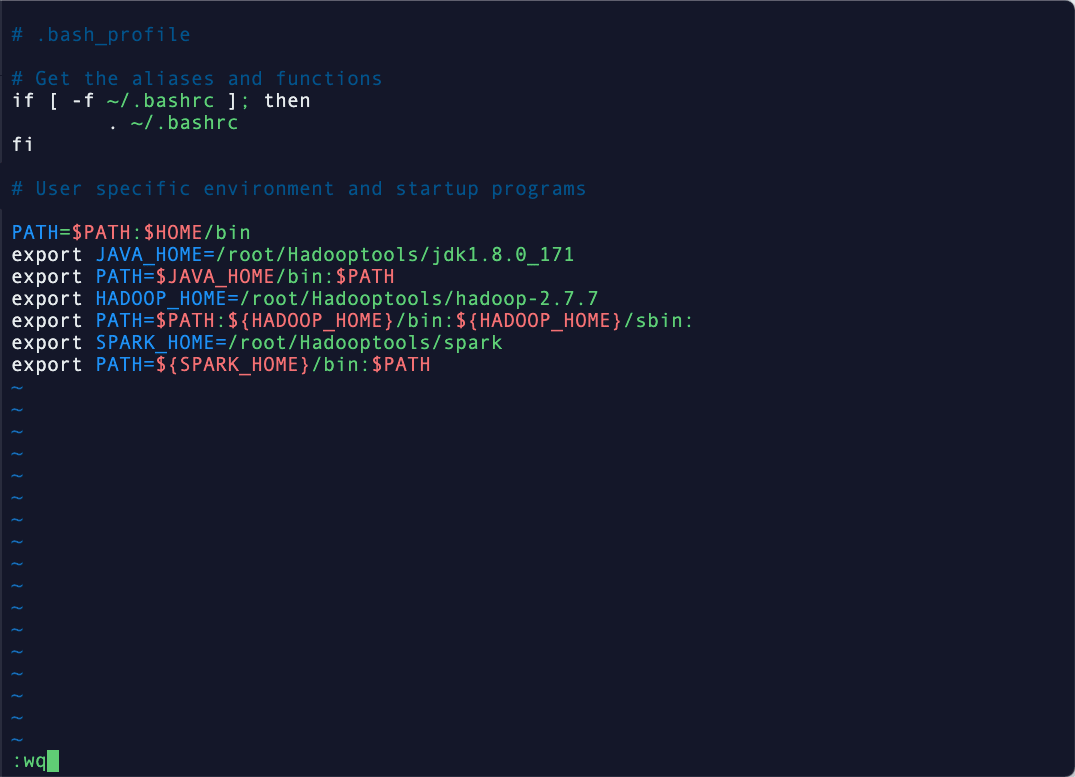
5)修改环境变量,添加 spark 先输入命令编辑.bash_profile vim /root/.bash_profile然后在末尾添加以下内容:
export SPARK_HOME=/root/Hadooptools/spark
export PATH=${SPARK_HOME}/bin:$PATH
6)输入命令使修改的配置生效:source /root/.bash_profile

7)编辑 spark-env.sh
- 先进入 conf 文件夹
cd /root/Hadooptools/spark/conf/ - 首先复制一份 spark-env.sh,并将其改名
cp spark-env.sh.template spark-env.sh - 编辑 spark-env.sh
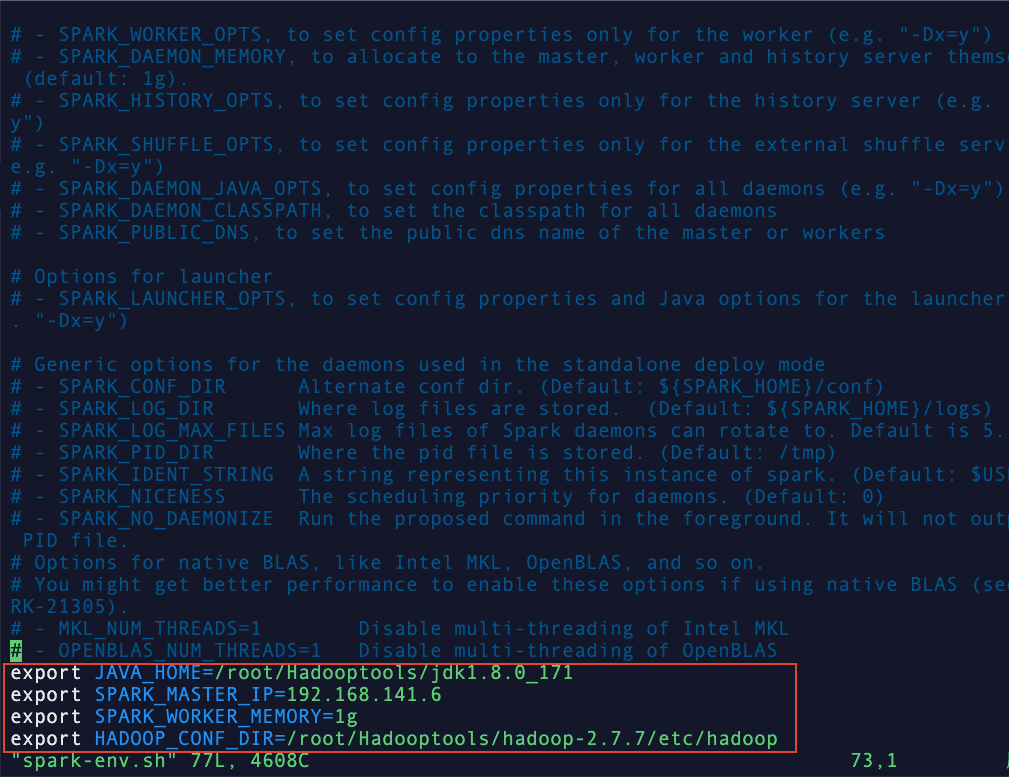
vim spark-env.sh将以下内容添加到文件中:
export JAVA_HOME=/root/Hadooptools/jdk1.8.0_171
export SPARK_MASTER_IP=192.168.141.6
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/root/Hadooptools/hadoop-2.7.7/etc/hadoop
8)添加 s1,s2 节点信息 vim /root/Hadooptools/spark/conf/slaves

9)将 spark 文件夹复制到 s1,s2 依次运行下面的命令:
cd /root/Hadooptools
scp -r spark root@s1:/root/Hadooptools/
scp -r spark root@s2:/root/Hadooptools/
10)进入 spark 文件夹,启动 spark 依次运行以下命令:
cd /root/Hadooptools/spark/sbin/
./start-all.sh

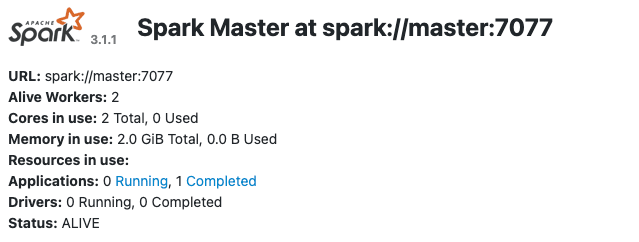
11)在宿主机的浏览器中访问地址:http://192.168.141.6:8080 ,查看是否能成功访问,如果可以,则 spark 启动成功。
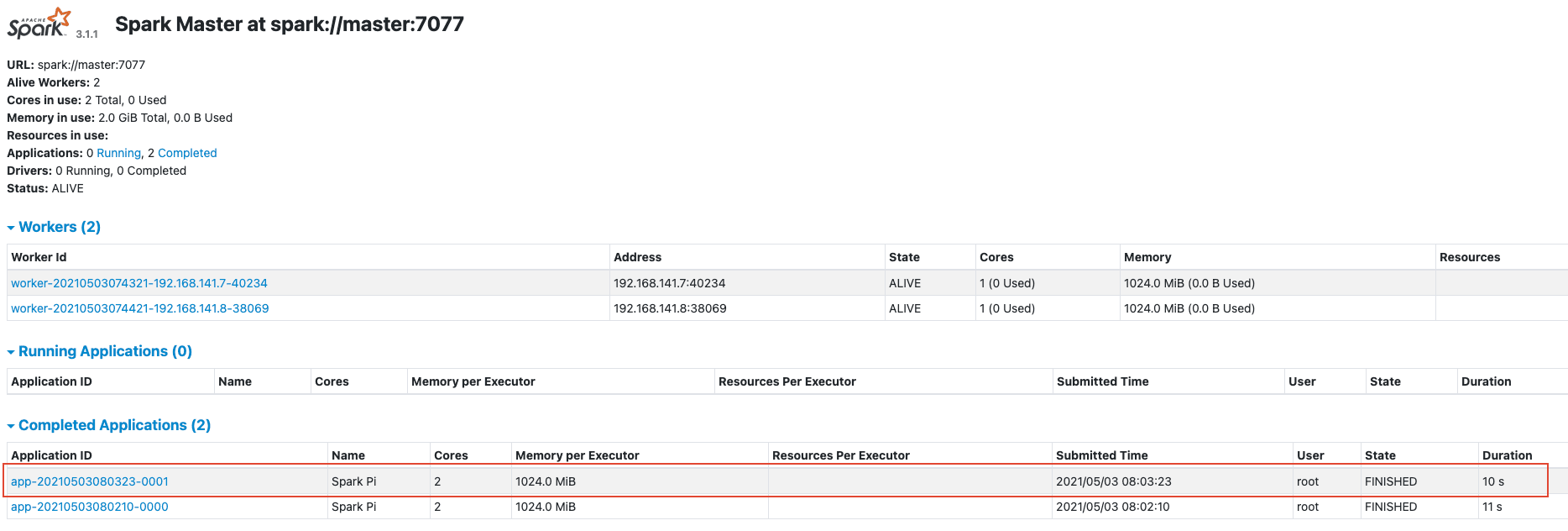
12)测试 spark 运行是否正常依次运行以下命令:
cd /root
./Hadooptools/spark/bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 /root/Hadooptools/spark/examples//jars/spark-examples_2.12-3.1.1.jar 100
然后打开 spark 的 WebUI 查看运行情况http://192.168.141.6:8080
附录
用 mac 自带的 iterm 连接虚拟机
输入命令 ssh root@192.168.141.6